


Equipo Creatify
COMPARTIR



EN ESTE ARTÍCULO
La mayoría de los generadores de video de IA te dan el efecto del valle inquietante: bocas que se mueven, ojos que no, cuerpos que permanecen congelados como una figura de cartón. Aurora está creada para arreglar eso.

Aurora es el modelo de transformador de difusión (DiT) propietario de Creatify para la síntesis de avatares impulsada por audio. Dale una foto y un clip de audio, y genera un video de estudio de esa persona hablando, presentando o cantando, con expresiones faciales sincronizadas, movimientos naturales de ojos, respiración y gestos completos del torso superior. No es solo sincronización labial. Es una actuación completa.
El modelo ya ha sido integrado en ElevenLabs, Runware y fal.ai como uno de los primeros modelos de generación de video - una señal de hacia dónde se dirige la generación de video con IA.
Esta guía cubre cómo obtener los mejores resultados con ella.
Qué hace diferente a Aurora
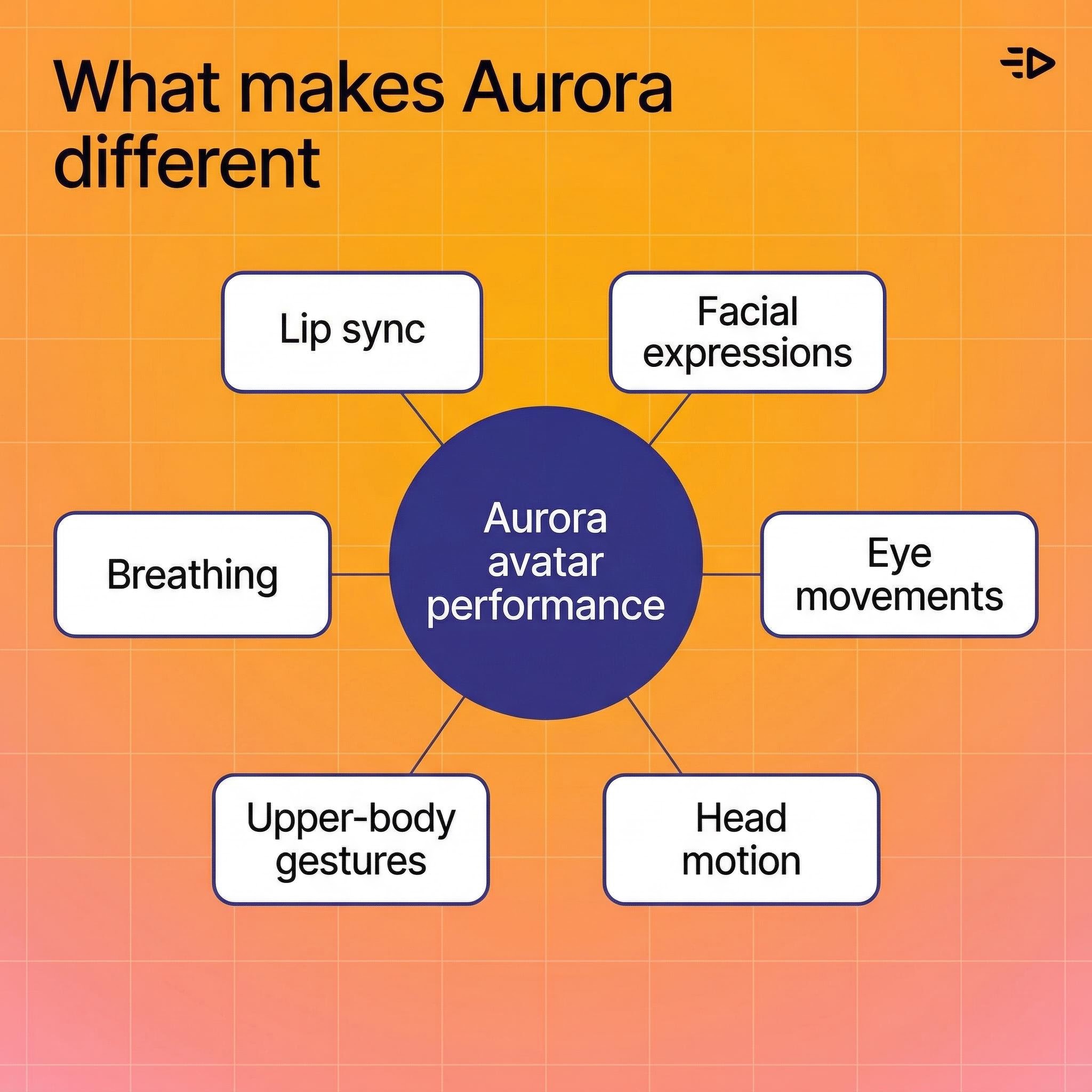
La mayoría de las herramientas de cabezas parlantes animan la boca y listo. Aurora trata al avatar como una persona completa, estableciendo un nuevo referente para la generación de video de IA realista.
Esto es lo que el modelo realmente produce:
Sincronización labial que sigue el audio con precisión, incluyendo formas sutiles de boca para diferentes fonemas
Expresiones faciales que coinciden con el tono vocal y la entrega emocional
Movimientos oculares - parpadeos, cambios de mirada, enfoque natural
Movimiento de cabeza - asentimientos, inclinaciones, cambios sutiles de posición
Gestos del torso superior - movimientos de manos, cambios de hombros, el tipo de movimiento natural que hace que una cabeza parlante se sienta real en lugar de robótica
Respiración - movimiento del pecho entre oraciones
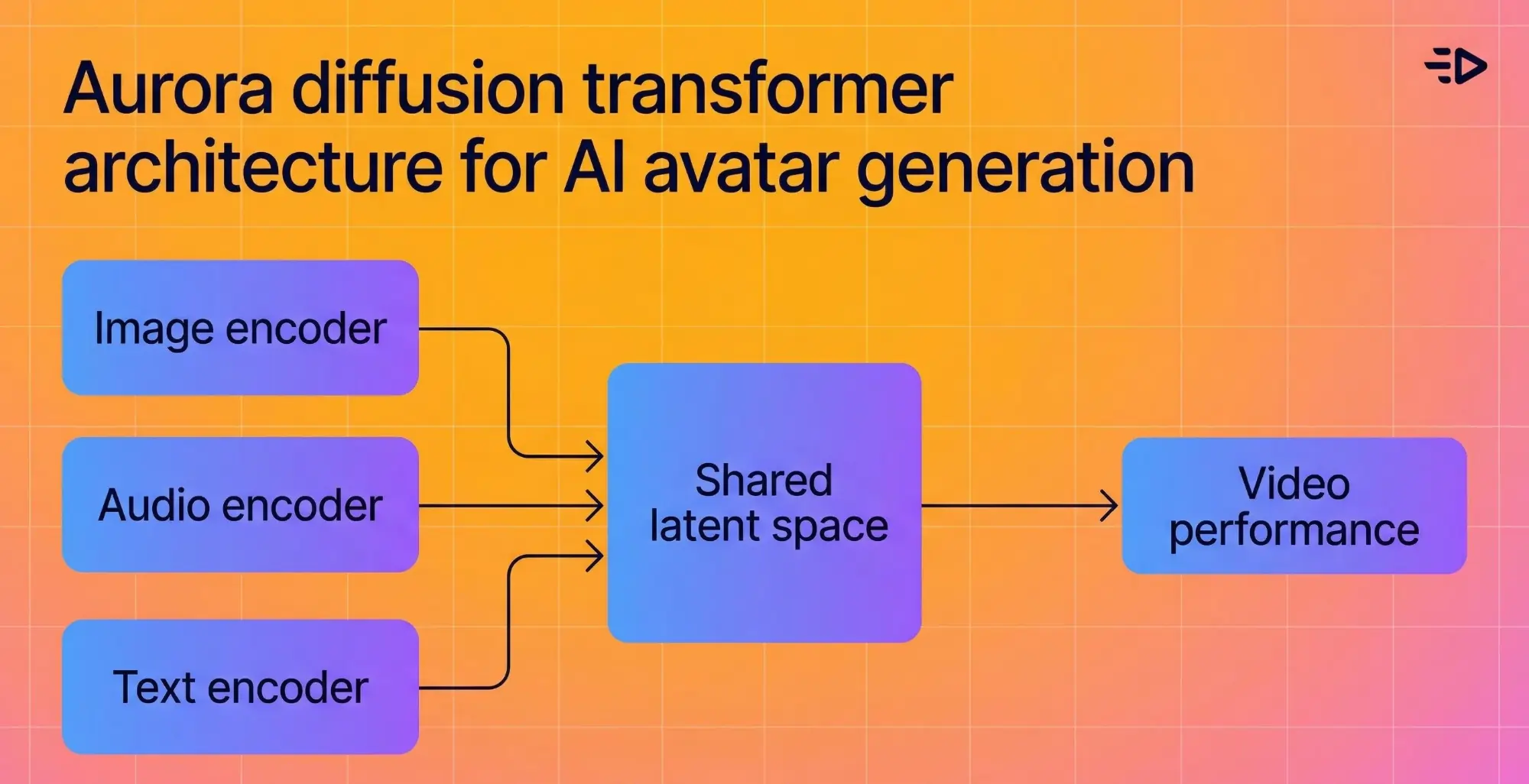
La arquitectura subyacente fusiona un codificador de imagen, un codificador de texto y un codificador de audio en un espacio latente compartido, por lo que el modelo entiende el contexto emocional de lo que se está diciendo y lo refleja visualmente. Si el audio suena entusiasta, el avatar se ve entusiasta.
Lo que puedes crear con ella

Aurora soporta una amplia gama de tipos de contenido más allá de simples cabezas parlantes, convirtiéndola en una herramienta poderosa para flujos de trabajo de generación de video con IA:
Demostraciones de productos - Muestra a un portavoz sosteniendo un producto, apuntando a él y explicando sus beneficios. Funciona con productos de cuidado personal, tecnología, bienes de consumo, lo que sea.
Anuncios estilo UGC - Formato selfie, ligero temblor de cámara en mano, entrega casual. Difícil de distinguir del contenido de un creador real.
Clips de podcast - El avatar mira ligeramente hacia un lado como si hablara con un coanfitrión, con una expresión comprometida y conversacional.
Contenido multilingüe - Genera el mismo video en cualquier idioma sin volver a grabar. Aurora mantiene los movimientos labiales del avatar sincronizados con el nuevo audio.
Avatares cantantes - Dale una portada de álbum y una canción, y el avatar la interpreta. Útil para marketing musical o contenido de entretenimiento.
Personajes animados - Funciona con personajes ilustrados y arte estilizado, no solo fotos realistas.
Obtener los mejores resultados con la generación de video de IA
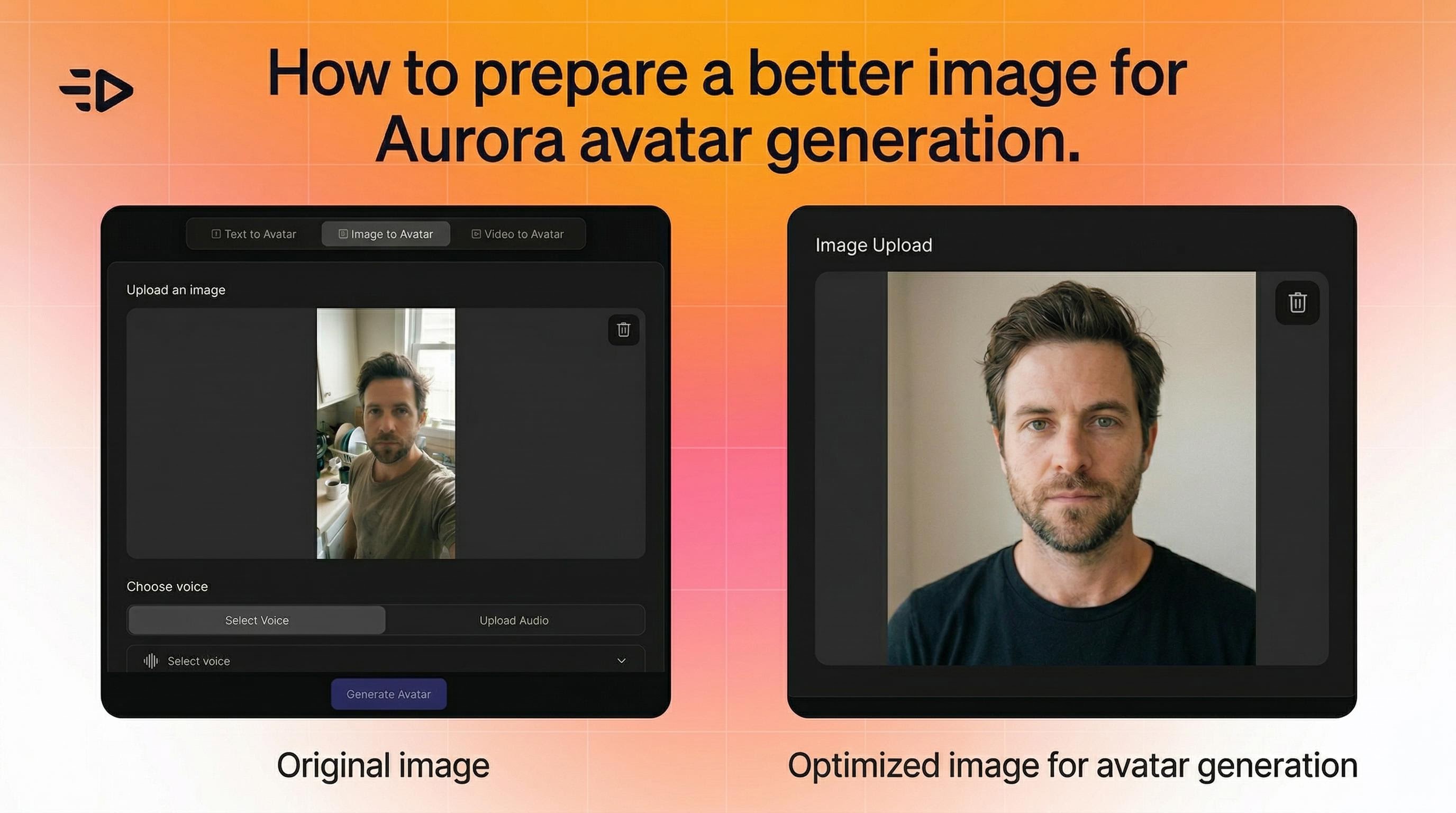
1. Comienza con la imagen correcta
Aurora es flexible - funciona con fotos, renders y arte de personajes. Pero algunas cosas ayudan:
El sujeto debe ser claramente visible y distinguible en el encuadre
Para videos consistentes en múltiples escenas, mantén un encuadre similar en todas las imágenes (por ejemplo, todas las tomas de retrato)
Si el movimiento parece antinatural, intenta con una imagen que tenga una pose más limpia y neutra
No hay limitaciones estrictas sobre el ángulo, iluminación o composición. Aurora se ajusta dinámicamente.
2. Usa el Modelo de Voz V3
Esto no es negociable para obtener resultados de calidad. El Modelo de Voz V3 ofrece la sincronización labial más precisa y el rango expresivo más amplio. Modelos de voz más antiguos producen resultados notablemente peores.
Mantén la velocidad del habla moderada y clara. Si la sincronización parece ligeramente incorrecta, desacelerar un poco la voz generalmente lo soluciona. Añade pausas naturales entre frases: dan al avatar espacio para respirar y hacen que la actuación se sienta más humana.
3. Domina tu prompt
Aquí es donde la mayoría deja resultados sobre la mesa. El prompt le dice a Aurora cómo debe comportarse el avatar: no solo cómo se ve, sino cómo se mueve, qué emoción transmite y cómo interactúa con la escena.
Usa esto como tu prompt base para cualquier video estándar de cabezas parlantes:
Entrevista de estudio en 4K, plano medio-cercano (recorte de los hombros para arriba). Fondo ininterrumpido de color gris claro sólido, luz principal suave y uniforme - sin cambios de iluminación. El presentador mira a la lente, con contacto visual estable. Las manos permanecen bajo el marco, el cuerpo perfectamente quieto. Ultra nítido.
Desde ahí, integra señales de comportamiento específicas a tu caso de uso.
Ejemplos de prompts por formato:
Caso de Uso | Prompt Conductual para Añadir |
|---|---|
Demostración de producto | La persona que sostiene el producto muestra la etiqueta frente a la cámara mientras explica, señalando de vez en cuando. |
Cabeza parlante natural | La persona habla y mira directamente y naturalmente a la cámara con movimientos de pecho al respirar. Gestos naturales al explicar y movimientos oculares. |
Podcast | La persona está mirando y de cara a un lado como si hablara con alguien en esa dirección, con expresión comprometida mostrando interés en el tema. |
Selfie estilo UGC | La persona habla frente a la cámara con una mano no visible. La cámara tiene un ligero temblor como si estuviera sostenida a mano. |
Reseña de producto entusiasta | Las manos de la persona se mueven con entusiasmo tratando de explicar el beneficio del producto. |
Cuanto más específico seas con el tono emocional y el comportamiento físico, mejor será el resultado. Los prompts vagos producen resultados genéricos.
Consejo profesional: Usa GPT para combinar la configuración cinematográfica base con tu caso de uso específico. Pídele: "Genera un prompt optimizado de Aurora para una demostración de producto [X]" y combinará automáticamente el encuadre técnico con las señales de comportamiento adecuadas.
4. Ajusta el guidance del prompt
Aurora tiene un parámetro prompt_guidance que va de 0 a 4. Controla qué tan estrictamente sigue el modelo tu prompt frente a permitir variación natural.
Comienza en 1 para la mayoría de las escenas. Le da al modelo espacio para desenvolverse naturalmente mientras sigue la dirección.
Auméntalo si el avatar se desvía del prompt o no sigue las señales de comportamiento que estableciste.
Redúcelo si la actuación se siente rígida o mecánica.
5. Alinea emocionalmente audio, imagen y el prompt
El error más común: usar una pista de audio enérgica y animada con una imagen de rostro neutral y un prompt de comportamiento calmado. El modelo fusiona los tres inputs. Si están tirando en direcciones diferentes, el resultado se siente inconsistente.
Si tu audio es entusiasta, tu prompt debería llamar para un comportamiento enérgico y expresivo. Si es calmado e informativo, tu prompt debería reflejar eso. Cuanto más alineados estén estos tres inputs, más convincente será el resultado.
Rápida resolución de problemas
Problema | Solución |
|---|---|
La sincronización labial se siente mal | Disminuir ligeramente la velocidad de la voz |
El movimiento parece antinatural | Intenta con una imagen diferente con una pose más limpia |
El avatar se desvía del prompt | Aumenta el prompt_guidance |
La actuación se siente demasiado robótica | Reduce el prompt_guidance; añade señales de comportamiento más suaves |
Inconsistencia entre escenas | Utiliza imágenes con encuadre y estilo similares |

La visión general
Aurora representa un avance significativo en la generación de video con IA — no porque sea una novedad, sino porque soluciona un problema real de producción. Crear videos de avatares de alta calidad solía requerir una cámara, un estudio, un intérprete y un flujo de trabajo de postproducción. Ahora solo requiere una foto y un guion.
Para los marketers de rendimiento que realizan campañas pagadas, eso cambia la matemática de las pruebas creativas. Para las agencias que gestionan múltiples clientes, cambia la economía de la producción de video. Para cualquiera que haya pasado por alto los anuncios en video debido al costo o la complejidad, elimina completamente la barrera.
El modelo está en vivo en Creatify, y las integraciones con ElevenLabs, Runware y fal.ai significan que es cada vez más accesible como una capacidad independiente para desarrolladores y creadores que construyen sobre infraestructura de IA.
Una foto. Un clip de audio. Un video que parece grabado en un estudio.
La mayoría de los generadores de video de IA te dan el efecto del valle inquietante: bocas que se mueven, ojos que no, cuerpos que permanecen congelados como una figura de cartón. Aurora está creada para arreglar eso.
Aurora es el modelo de transformador de difusión (DiT) propietario de Creatify para la síntesis de avatares impulsada por audio. Dale una foto y un clip de audio, y genera un video de estudio de esa persona hablando, presentando o cantando, con expresiones faciales sincronizadas, movimientos naturales de ojos, respiración y gestos completos del torso superior. No es solo sincronización labial. Es una actuación completa.
El modelo ya ha sido integrado en ElevenLabs, Runware y fal.ai como uno de los primeros modelos de generación de video - una señal de hacia dónde se dirige la generación de video con IA.
Esta guía cubre cómo obtener los mejores resultados con ella.
Qué hace diferente a Aurora
La mayoría de las herramientas de cabezas parlantes animan la boca y listo. Aurora trata al avatar como una persona completa, estableciendo un nuevo referente para la generación de video de IA realista.
Esto es lo que el modelo realmente produce:
Sincronización labial que sigue el audio con precisión, incluyendo formas sutiles de boca para diferentes fonemas
Expresiones faciales que coinciden con el tono vocal y la entrega emocional
Movimientos oculares - parpadeos, cambios de mirada, enfoque natural
Movimiento de cabeza - asentimientos, inclinaciones, cambios sutiles de posición
Gestos del torso superior - movimientos de manos, cambios de hombros, el tipo de movimiento natural que hace que una cabeza parlante se sienta real en lugar de robótica
Respiración - movimiento del pecho entre oraciones
La arquitectura subyacente fusiona un codificador de imagen, un codificador de texto y un codificador de audio en un espacio latente compartido, por lo que el modelo entiende el contexto emocional de lo que se está diciendo y lo refleja visualmente. Si el audio suena entusiasta, el avatar se ve entusiasta.
Lo que puedes crear con ella
Aurora soporta una amplia gama de tipos de contenido más allá de simples cabezas parlantes, convirtiéndola en una herramienta poderosa para flujos de trabajo de generación de video con IA:
Demostraciones de productos - Muestra a un portavoz sosteniendo un producto, apuntando a él y explicando sus beneficios. Funciona con productos de cuidado personal, tecnología, bienes de consumo, lo que sea.
Anuncios estilo UGC - Formato selfie, ligero temblor de cámara en mano, entrega casual. Difícil de distinguir del contenido de un creador real.
Clips de podcast - El avatar mira ligeramente hacia un lado como si hablara con un coanfitrión, con una expresión comprometida y conversacional.
Contenido multilingüe - Genera el mismo video en cualquier idioma sin volver a grabar. Aurora mantiene los movimientos labiales del avatar sincronizados con el nuevo audio.
Avatares cantantes - Dale una portada de álbum y una canción, y el avatar la interpreta. Útil para marketing musical o contenido de entretenimiento.
Personajes animados - Funciona con personajes ilustrados y arte estilizado, no solo fotos realistas.
Obtener los mejores resultados con la generación de video de IA
1. Comienza con la imagen correcta
Aurora es flexible - funciona con fotos, renders y arte de personajes. Pero algunas cosas ayudan:
El sujeto debe ser claramente visible y distinguible en el encuadre
Para videos consistentes en múltiples escenas, mantén un encuadre similar en todas las imágenes (por ejemplo, todas las tomas de retrato)
Si el movimiento parece antinatural, intenta con una imagen que tenga una pose más limpia y neutra
No hay limitaciones estrictas sobre el ángulo, iluminación o composición. Aurora se ajusta dinámicamente.
2. Usa el Modelo de Voz V3
Esto no es negociable para obtener resultados de calidad. El Modelo de Voz V3 ofrece la sincronización labial más precisa y el rango expresivo más amplio. Modelos de voz más antiguos producen resultados notablemente peores.
Mantén la velocidad del habla moderada y clara. Si la sincronización parece ligeramente incorrecta, desacelerar un poco la voz generalmente lo soluciona. Añade pausas naturales entre frases: dan al avatar espacio para respirar y hacen que la actuación se sienta más humana.
3. Domina tu prompt
Aquí es donde la mayoría deja resultados sobre la mesa. El prompt le dice a Aurora cómo debe comportarse el avatar: no solo cómo se ve, sino cómo se mueve, qué emoción transmite y cómo interactúa con la escena.
Usa esto como tu prompt base para cualquier video estándar de cabezas parlantes:
Entrevista de estudio en 4K, plano medio-cercano (recorte de los hombros para arriba). Fondo ininterrumpido de color gris claro sólido, luz principal suave y uniforme - sin cambios de iluminación. El presentador mira a la lente, con contacto visual estable. Las manos permanecen bajo el marco, el cuerpo perfectamente quieto. Ultra nítido.
Desde ahí, integra señales de comportamiento específicas a tu caso de uso.
Ejemplos de prompts por formato:
Caso de Uso | Prompt Conductual para Añadir |
|---|---|
Demostración de producto | La persona que sostiene el producto muestra la etiqueta frente a la cámara mientras explica, señalando de vez en cuando. |
Cabeza parlante natural | La persona habla y mira directamente y naturalmente a la cámara con movimientos de pecho al respirar. Gestos naturales al explicar y movimientos oculares. |
Podcast | La persona está mirando y de cara a un lado como si hablara con alguien en esa dirección, con expresión comprometida mostrando interés en el tema. |
Selfie estilo UGC | La persona habla frente a la cámara con una mano no visible. La cámara tiene un ligero temblor como si estuviera sostenida a mano. |
Reseña de producto entusiasta | Las manos de la persona se mueven con entusiasmo tratando de explicar el beneficio del producto. |
Cuanto más específico seas con el tono emocional y el comportamiento físico, mejor será el resultado. Los prompts vagos producen resultados genéricos.
Consejo profesional: Usa GPT para combinar la configuración cinematográfica base con tu caso de uso específico. Pídele: "Genera un prompt optimizado de Aurora para una demostración de producto [X]" y combinará automáticamente el encuadre técnico con las señales de comportamiento adecuadas.
4. Ajusta el guidance del prompt
Aurora tiene un parámetro prompt_guidance que va de 0 a 4. Controla qué tan estrictamente sigue el modelo tu prompt frente a permitir variación natural.
Comienza en 1 para la mayoría de las escenas. Le da al modelo espacio para desenvolverse naturalmente mientras sigue la dirección.
Auméntalo si el avatar se desvía del prompt o no sigue las señales de comportamiento que estableciste.
Redúcelo si la actuación se siente rígida o mecánica.
5. Alinea emocionalmente audio, imagen y el prompt
El error más común: usar una pista de audio enérgica y animada con una imagen de rostro neutral y un prompt de comportamiento calmado. El modelo fusiona los tres inputs. Si están tirando en direcciones diferentes, el resultado se siente inconsistente.
Si tu audio es entusiasta, tu prompt debería llamar para un comportamiento enérgico y expresivo. Si es calmado e informativo, tu prompt debería reflejar eso. Cuanto más alineados estén estos tres inputs, más convincente será el resultado.
Rápida resolución de problemas
Problema | Solución |
|---|---|
La sincronización labial se siente mal | Disminuir ligeramente la velocidad de la voz |
El movimiento parece antinatural | Intenta con una imagen diferente con una pose más limpia |
El avatar se desvía del prompt | Aumenta el prompt_guidance |
La actuación se siente demasiado robótica | Reduce el prompt_guidance; añade señales de comportamiento más suaves |
Inconsistencia entre escenas | Utiliza imágenes con encuadre y estilo similares |
La visión general
Aurora representa un avance significativo en la generación de video con IA — no porque sea una novedad, sino porque soluciona un problema real de producción. Crear videos de avatares de alta calidad solía requerir una cámara, un estudio, un intérprete y un flujo de trabajo de postproducción. Ahora solo requiere una foto y un guion.
Para los marketers de rendimiento que realizan campañas pagadas, eso cambia la matemática de las pruebas creativas. Para las agencias que gestionan múltiples clientes, cambia la economía de la producción de video. Para cualquiera que haya pasado por alto los anuncios en video debido al costo o la complejidad, elimina completamente la barrera.
El modelo está en vivo en Creatify, y las integraciones con ElevenLabs, Runware y fal.ai significan que es cada vez más accesible como una capacidad independiente para desarrolladores y creadores que construyen sobre infraestructura de IA.
Una foto. Un clip de audio. Un video que parece grabado en un estudio.

¿Listo para convertir tu producto en un video atractivo?











