


Creatify チーム
シェア



この記事では
ほとんどのAIビデオジェネレーターは、不気味の谷を提供します。口が動き、目が動かず、体が段ボールの切り抜きのように凍りついているようです。Auroraはそれを修正するために構築されました。

Auroraは、音声駆動のアバター合成のためのCreatifyの独自の拡散トランスフォーマー(DiT)モデルです。写真1枚と音声クリップを与えるだけで、その人物が話したり、プレゼンしたり、歌ったりするスタジオ品質のビデオを生成します。表情の同期、自然な目の動き、呼吸、完全な上半身のジェスチャーを伴います。ただのリップシンクではなく、完全なパフォーマンスです。
このモデルはすでにElevenLabs、Runware、fal.aiに最初のビデオ生成モデルの1つとして統合されています。AIビデオ生成の未来を示しています。
このガイドでは、最良の結果を得る方法を説明します。
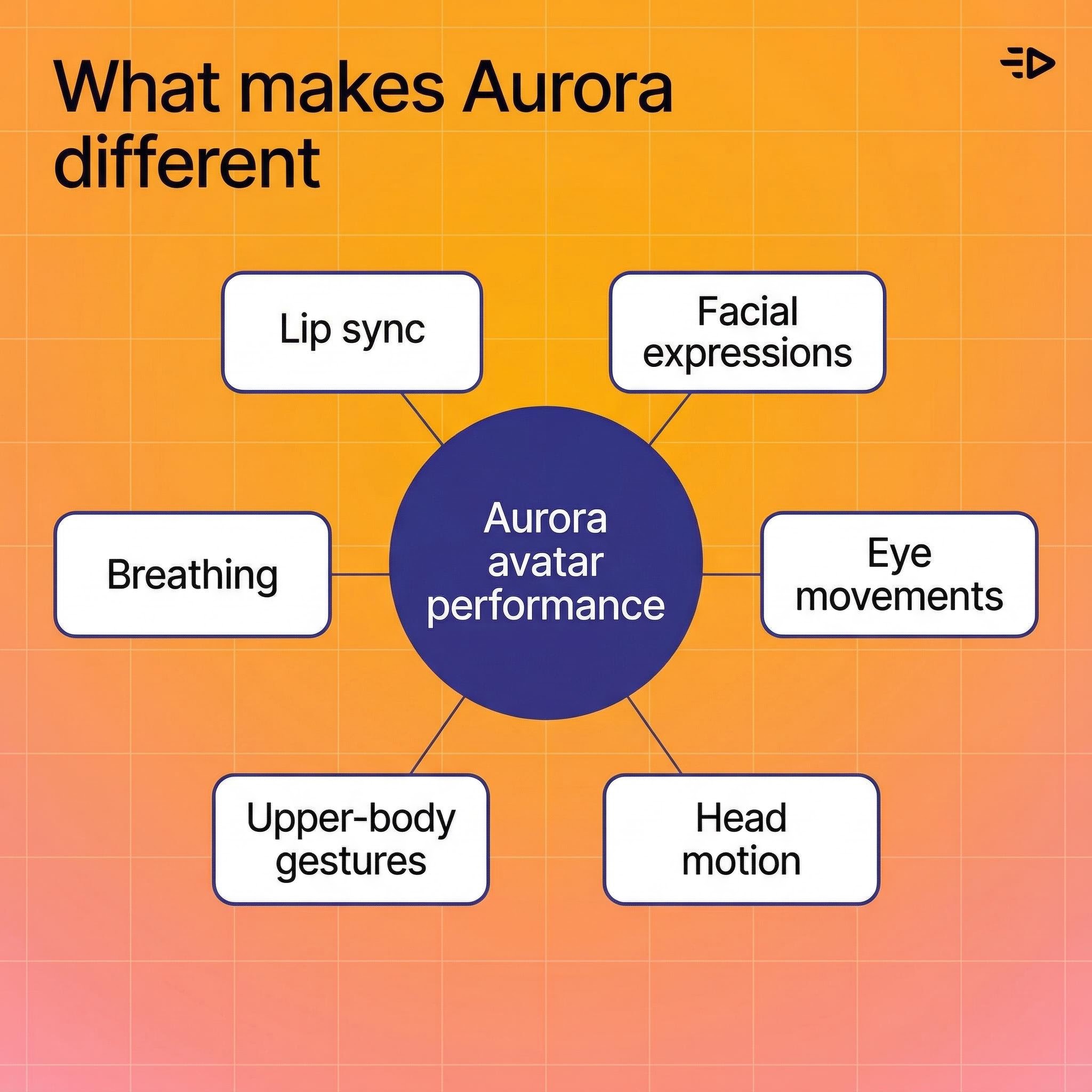
Auroraが異なる理由
ほとんどのトーキングヘッドツールは口をアニメートして終わりですが、Auroraはアバターを完全な人間として扱い、リアルなAIビデオ生成の新しい基準を設定します。
このモデルが実際に生成するものは次のとおりです:
リップシンク - オーディオに合わせて正確にトラッキングし、さまざまな音素に対する微妙な口の形も含みます
表情 - 声のトーンと感情的な伝達に一致
目の動き - 瞬き、視線のシフト、自然なフォーカス
頭の動き - うなずき、傾き、微妙な位置の変化
上半身のジェスチャー - 手の動き、肩のシフト、ロボットではなく実際に話している人に見える自然な動き
呼吸 - 文の間の胸の動き
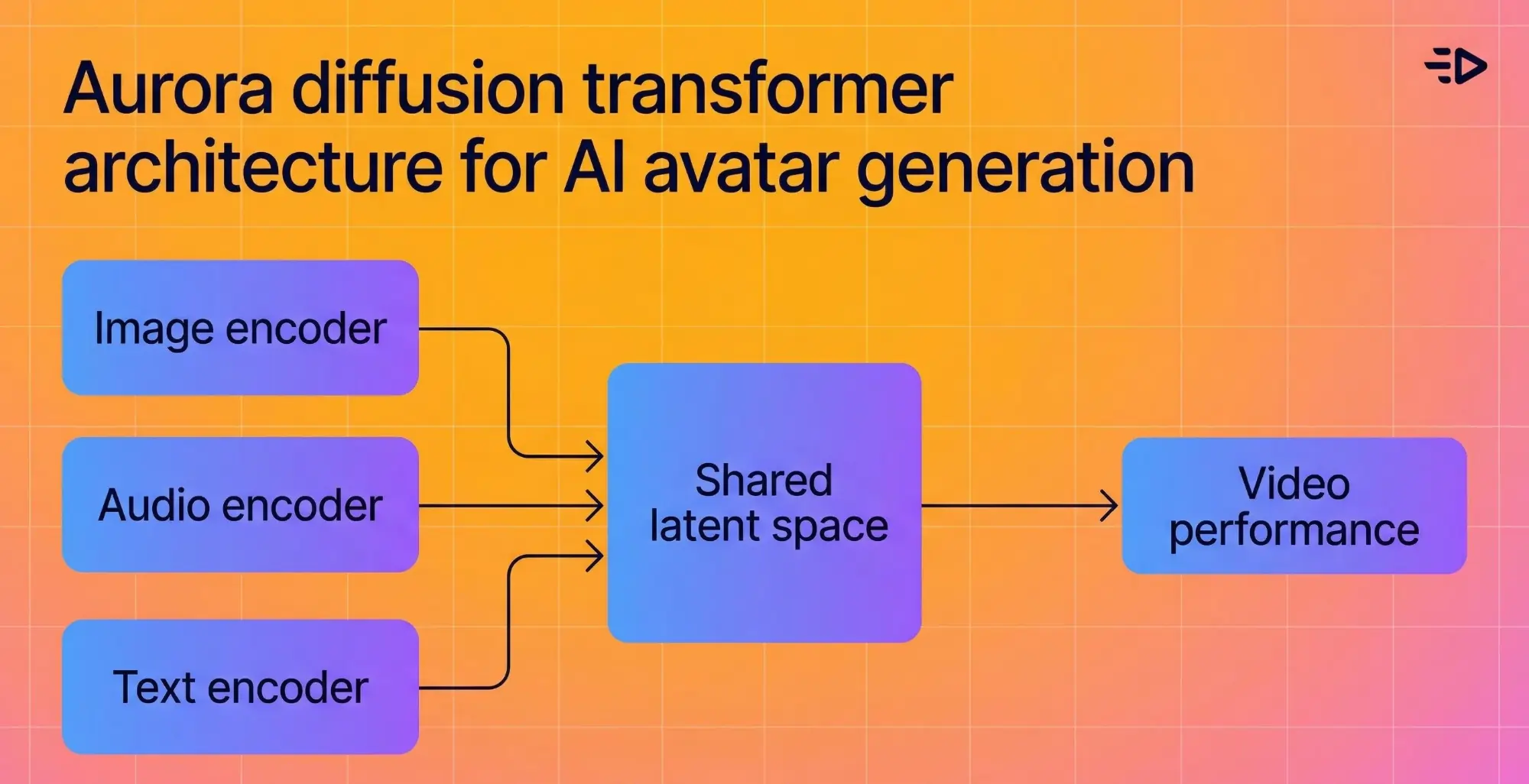
基礎となるアーキテクチャは、イメージエンコーダー、テキストエンコーダー、およびオーディオエンコーダーを共有の潜在空間に融合させ、モデルが言っていることの感情的なコンテキストを理解し、それを視覚的に反映させます。オーディオが熱狂的に聞こえる場合、アバターも熱狂的に見えます。
何を構築できるか

Auroraはシンプルなトーキングヘッドを超えた幅広いコンテンツタイプをサポートし、それをAIビデオ生成ワークフローの強力なツールにします:
製品デモ - 商品を手に持ち、それを指し示し、利点を説明するスポークスパーソンを表示します。スキンケア、技術、消費財、何にでも対応。
UGCスタイルの広告 - セルフィー形式、微妙な手持ちカメラの揺れ、カジュアルな配信。現実のクリエーターコンテンツと見分けがつかない。
ポッドキャストクリップ - アバターが少し横を向いてコーホストと話しているかのように見え、興味を持った会話の表情を持ちます。
多言語コンテンツ - 再撮影せずに任意の言語で同じビデオを生成します。Auroraは新しいオーディオに合わせてアバターのリップの動きを同期します。
歌うアバター - アルバムアートと曲を与え、アバターがそれをパフォーマンスします。音楽マーケティングやエンターテインメントコンテンツに役立つ。
アニメキャラクター - イラストキャラクターやスタイライズされたアートと連携し、リアルな写真だけではありません。
AIビデオ生成で最良の結果を得る方法
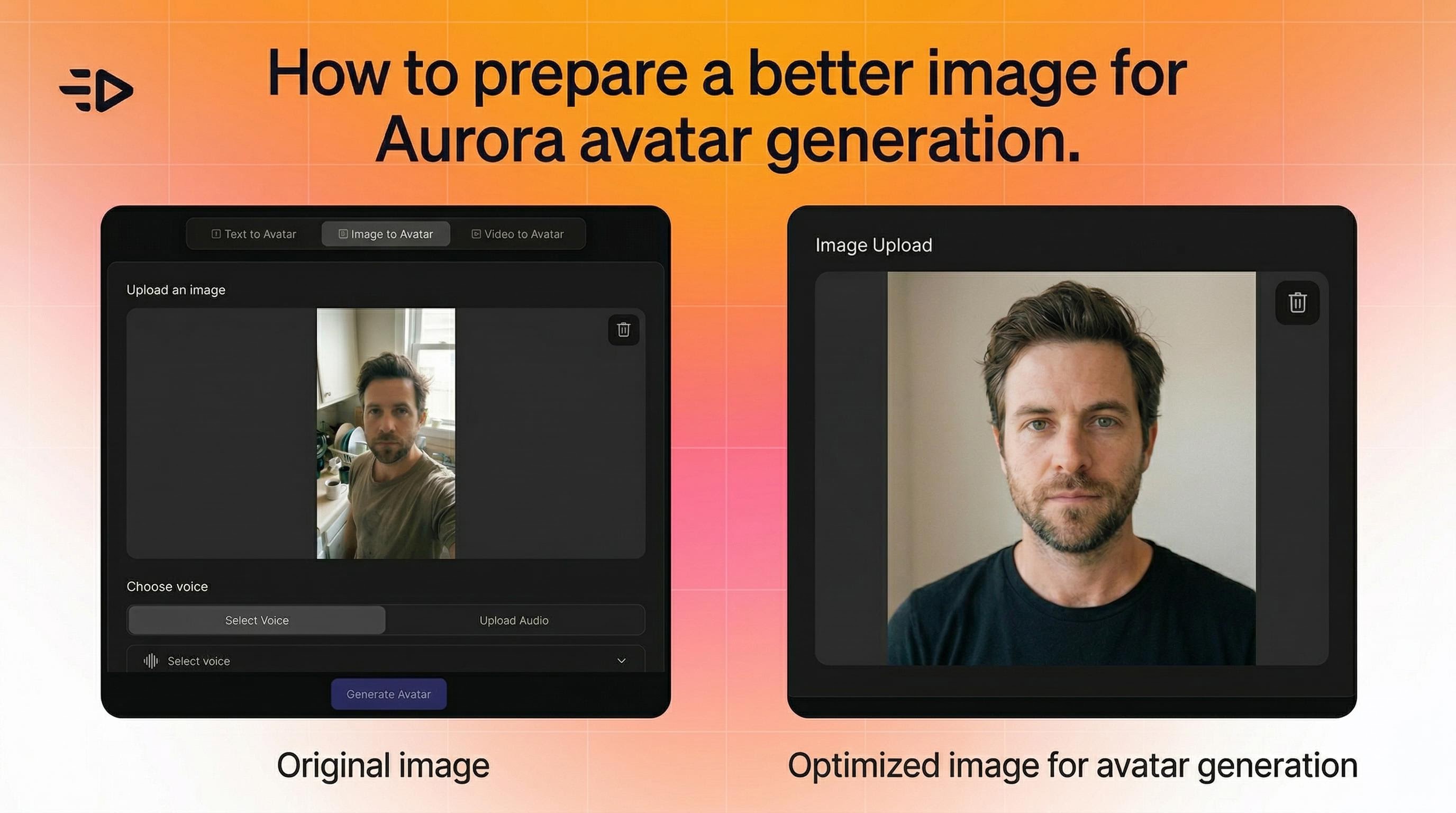
1. 正しいイメージから始める
Auroraは柔軟で、写真、レンダー、キャラクターアートと連携します。ただ、以下のことが役立ちます:
被写体がフレーム内で明確に見え、区別できること
一貫したマルチシーンビデオのためには、すべての画像で同様のフレーミングを維持する(例: すべて縦撮り)
動きが不自然に見える場合は、よりクリーンで中立的なポーズの画像を試してください
角度、照明、構図について厳しい制限はありません。Auroraは動的に調整します。
2. Voice Model V3を使用
品質の良い結果を得るためにこれは譲れません。Voice Model V3は最も正確なリップシンクと最も広範囲の表現力を提供します。古いボイスモデルは明らかに悪化した出力を生成します。
話す速度を適度にし、クリアに保ちます。同期がわずかにずれている場合、音声をわずかに遅らせることで通常は解決します。文章の間に自然なポーズを加えてください - これはアバターに呼吸の余裕を与え、パフォーマンスをより人間らしく感じさせます。
3. プロンプトをマスターする
これは多くの人が結果をテーブルに残すところです。プロンプトはAuroraにアバターがどのように振る舞うべきかを伝えます - ただ外見だけでなく、動き、感情の伝達、シーンとのインタラクトの方法も。
標準的なトーキングヘッドビデオのベースプロンプトとしてこれを使用してください:
4Kスタジオインタビュー、中間クローズアップ(肩から上のクロップ)。ソリッドなライトグレーのシームレスな背景、均一なソフトキーライト - 照明の変化なし。プレゼンテーターはレンズを見つめ、安定したアイコンタクトを保つ。手はフレームの下にとどまり、体は完全に静止しています。超シャープ。
そこから、あなたのユースケースに特有の行動キューを重ね合わせます。
フォーマット別のプロンプト例:
ユースケース | 追加する行動プロンプト |
|---|---|
製品デモ | 製品を持っている人が、ラベルをカメラに向けて示し、時々それを指し示しながら説明している。 |
自然なトーキングヘッド | 人が話してカメラに自然に向かい、呼吸の胸の動きとともに。自然な説明のジェスチャーと目の動き。 |
ポッドキャスト | 人が誰かに向かって話しているかのように顔を横に向け、興味を持った表情を見せている。 |
UGCセルフィー | 人がカメラの前で片手が見えない状態で話している。カメラが微妙に揺れている。 |
熱烈な製品レビュー | 人の手が、製品の利点を説明しようとして熱烈に動いている。 |
感情のトーンと物理的な振る舞いを具体的にすれば具体的にするほど、出力はより良くなります。曖昧なプロンプトは一般的な結果を生み出します。
プロのヒント:GPTを使って、ベースのシネマティック設定を具体的なユースケースと組み合わせます。「[X] 製品デモのための最適化されたAuroraプロンプトを生成する」とプロンプトを入力すれば、それが技術的なフレーミングを適切な行動の指示と自動的にブレンドします。
4. プロンプトガイダンスを調整する
Auroraにはprompt_guidanceパラメータがあり、0から4までの範囲でプロンプトにどれだけ厳密に従うか、自然なバリエーションを許容するかを制御します。
ほとんどのシーンでは1から始めることをお勧めします。モデルが自然にパフォーマンスする余地を与えつつ、指示に従うようにします。
それを上げると、アバターがプロンプトから外れたり、設定した行動キューに従わなかったりするのを防ぎます。
それを下げると、パフォーマンスが固く機械的に感じられる場合に柔らかくします。
5. オーディオ、画像、プロンプトを感情的に一致させる
最も一般的な間違い: エネルギッシュでアップビートなオーディオトラックを、ニュートラルな顔のイメージや落ち着いた行動プロンプトと組み合わせて使用すること。モデルは3つの入力を融合します。これらが異なる方向に引っ張られると、出力は一貫性がないように感じられます。
オーディオが熱狂的であれば、プロンプトはエネルギッシュで表現力豊かな振る舞いを求めるべきです。落ち着いて情報的であれば、プロンプトもそれを反映するべきです。これら3つの入力がより整合性が取れていればいるほど、より説得力のある結果が得られます。
クイックトラブルシューティング
問題 | 修正 |
|---|---|
リップシンクがずれて感じる | 音声速度を少し遅くする |
動きが不自然に見える | よりクリーンなポーズの別の画像を試す |
アバターがプロンプトを外れる | プロンプトガイダンスを上げる |
パフォーマンスがあまりにもロボット的に感じる | プロンプトガイダンスを下げ、柔らかい行動キューを追加する |
シーン間の一貫性がない | フレーミングとスタイルが似た画像を使用する |

大局を見据えて
AuroraはAIビデオ生成において、実際の生産問題を解決するための重要な一歩を表しています。それはカメラ、スタジオ、パフォーマー、そしてポストプロダクションワークフローを必要とする高品質なアバタービデオを作成することを意味しますが、今では写真とスクリプトでそれが実現します。
有料キャンペーンを実行しているパフォーマンスマーケターにとって、それはクリエイティブテストの数学を変えます。複数のクライアントを管理する代理店にとって、それはビデオ制作の経済学を変えます。コストや複雑さのためにビデオ広告を見送ったことがある人にとって、それは完全に障壁を取り除きます。
このモデルはCreatifyで利用可能であり、ElevenLabs、Runware、fal.aiとの統合により、AIインフラストラクチャの上で開発しようとする開発者やクリエーターにとっては、独立した機能としてますますアクセスしやすくなっています。
1枚の写真。1つの音声クリップ。スタジオで撮影したかのように見えるビデオ。
ほとんどのAIビデオジェネレーターは、不気味の谷を提供します。口が動き、目が動かず、体が段ボールの切り抜きのように凍りついているようです。Auroraはそれを修正するために構築されました。
Auroraは、音声駆動のアバター合成のためのCreatifyの独自の拡散トランスフォーマー(DiT)モデルです。写真1枚と音声クリップを与えるだけで、その人物が話したり、プレゼンしたり、歌ったりするスタジオ品質のビデオを生成します。表情の同期、自然な目の動き、呼吸、完全な上半身のジェスチャーを伴います。ただのリップシンクではなく、完全なパフォーマンスです。
このモデルはすでにElevenLabs、Runware、fal.aiに最初のビデオ生成モデルの1つとして統合されています。AIビデオ生成の未来を示しています。
このガイドでは、最良の結果を得る方法を説明します。
Auroraが異なる理由
ほとんどのトーキングヘッドツールは口をアニメートして終わりですが、Auroraはアバターを完全な人間として扱い、リアルなAIビデオ生成の新しい基準を設定します。
このモデルが実際に生成するものは次のとおりです:
リップシンク - オーディオに合わせて正確にトラッキングし、さまざまな音素に対する微妙な口の形も含みます
表情 - 声のトーンと感情的な伝達に一致
目の動き - 瞬き、視線のシフト、自然なフォーカス
頭の動き - うなずき、傾き、微妙な位置の変化
上半身のジェスチャー - 手の動き、肩のシフト、ロボットではなく実際に話している人に見える自然な動き
呼吸 - 文の間の胸の動き
基礎となるアーキテクチャは、イメージエンコーダー、テキストエンコーダー、およびオーディオエンコーダーを共有の潜在空間に融合させ、モデルが言っていることの感情的なコンテキストを理解し、それを視覚的に反映させます。オーディオが熱狂的に聞こえる場合、アバターも熱狂的に見えます。
何を構築できるか
Auroraはシンプルなトーキングヘッドを超えた幅広いコンテンツタイプをサポートし、それをAIビデオ生成ワークフローの強力なツールにします:
製品デモ - 商品を手に持ち、それを指し示し、利点を説明するスポークスパーソンを表示します。スキンケア、技術、消費財、何にでも対応。
UGCスタイルの広告 - セルフィー形式、微妙な手持ちカメラの揺れ、カジュアルな配信。現実のクリエーターコンテンツと見分けがつかない。
ポッドキャストクリップ - アバターが少し横を向いてコーホストと話しているかのように見え、興味を持った会話の表情を持ちます。
多言語コンテンツ - 再撮影せずに任意の言語で同じビデオを生成します。Auroraは新しいオーディオに合わせてアバターのリップの動きを同期します。
歌うアバター - アルバムアートと曲を与え、アバターがそれをパフォーマンスします。音楽マーケティングやエンターテインメントコンテンツに役立つ。
アニメキャラクター - イラストキャラクターやスタイライズされたアートと連携し、リアルな写真だけではありません。
AIビデオ生成で最良の結果を得る方法
1. 正しいイメージから始める
Auroraは柔軟で、写真、レンダー、キャラクターアートと連携します。ただ、以下のことが役立ちます:
被写体がフレーム内で明確に見え、区別できること
一貫したマルチシーンビデオのためには、すべての画像で同様のフレーミングを維持する(例: すべて縦撮り)
動きが不自然に見える場合は、よりクリーンで中立的なポーズの画像を試してください
角度、照明、構図について厳しい制限はありません。Auroraは動的に調整します。
2. Voice Model V3を使用
品質の良い結果を得るためにこれは譲れません。Voice Model V3は最も正確なリップシンクと最も広範囲の表現力を提供します。古いボイスモデルは明らかに悪化した出力を生成します。
話す速度を適度にし、クリアに保ちます。同期がわずかにずれている場合、音声をわずかに遅らせることで通常は解決します。文章の間に自然なポーズを加えてください - これはアバターに呼吸の余裕を与え、パフォーマンスをより人間らしく感じさせます。
3. プロンプトをマスターする
これは多くの人が結果をテーブルに残すところです。プロンプトはAuroraにアバターがどのように振る舞うべきかを伝えます - ただ外見だけでなく、動き、感情の伝達、シーンとのインタラクトの方法も。
標準的なトーキングヘッドビデオのベースプロンプトとしてこれを使用してください:
4Kスタジオインタビュー、中間クローズアップ(肩から上のクロップ)。ソリッドなライトグレーのシームレスな背景、均一なソフトキーライト - 照明の変化なし。プレゼンテーターはレンズを見つめ、安定したアイコンタクトを保つ。手はフレームの下にとどまり、体は完全に静止しています。超シャープ。
そこから、あなたのユースケースに特有の行動キューを重ね合わせます。
フォーマット別のプロンプト例:
ユースケース | 追加する行動プロンプト |
|---|---|
製品デモ | 製品を持っている人が、ラベルをカメラに向けて示し、時々それを指し示しながら説明している。 |
自然なトーキングヘッド | 人が話してカメラに自然に向かい、呼吸の胸の動きとともに。自然な説明のジェスチャーと目の動き。 |
ポッドキャスト | 人が誰かに向かって話しているかのように顔を横に向け、興味を持った表情を見せている。 |
UGCセルフィー | 人がカメラの前で片手が見えない状態で話している。カメラが微妙に揺れている。 |
熱烈な製品レビュー | 人の手が、製品の利点を説明しようとして熱烈に動いている。 |
感情のトーンと物理的な振る舞いを具体的にすれば具体的にするほど、出力はより良くなります。曖昧なプロンプトは一般的な結果を生み出します。
プロのヒント:GPTを使って、ベースのシネマティック設定を具体的なユースケースと組み合わせます。「[X] 製品デモのための最適化されたAuroraプロンプトを生成する」とプロンプトを入力すれば、それが技術的なフレーミングを適切な行動の指示と自動的にブレンドします。
4. プロンプトガイダンスを調整する
Auroraにはprompt_guidanceパラメータがあり、0から4までの範囲でプロンプトにどれだけ厳密に従うか、自然なバリエーションを許容するかを制御します。
ほとんどのシーンでは1から始めることをお勧めします。モデルが自然にパフォーマンスする余地を与えつつ、指示に従うようにします。
それを上げると、アバターがプロンプトから外れたり、設定した行動キューに従わなかったりするのを防ぎます。
それを下げると、パフォーマンスが固く機械的に感じられる場合に柔らかくします。
5. オーディオ、画像、プロンプトを感情的に一致させる
最も一般的な間違い: エネルギッシュでアップビートなオーディオトラックを、ニュートラルな顔のイメージや落ち着いた行動プロンプトと組み合わせて使用すること。モデルは3つの入力を融合します。これらが異なる方向に引っ張られると、出力は一貫性がないように感じられます。
オーディオが熱狂的であれば、プロンプトはエネルギッシュで表現力豊かな振る舞いを求めるべきです。落ち着いて情報的であれば、プロンプトもそれを反映するべきです。これら3つの入力がより整合性が取れていればいるほど、より説得力のある結果が得られます。
クイックトラブルシューティング
問題 | 修正 |
|---|---|
リップシンクがずれて感じる | 音声速度を少し遅くする |
動きが不自然に見える | よりクリーンなポーズの別の画像を試す |
アバターがプロンプトを外れる | プロンプトガイダンスを上げる |
パフォーマンスがあまりにもロボット的に感じる | プロンプトガイダンスを下げ、柔らかい行動キューを追加する |
シーン間の一貫性がない | フレーミングとスタイルが似た画像を使用する |
大局を見据えて
AuroraはAIビデオ生成において、実際の生産問題を解決するための重要な一歩を表しています。それはカメラ、スタジオ、パフォーマー、そしてポストプロダクションワークフローを必要とする高品質なアバタービデオを作成することを意味しますが、今では写真とスクリプトでそれが実現します。
有料キャンペーンを実行しているパフォーマンスマーケターにとって、それはクリエイティブテストの数学を変えます。複数のクライアントを管理する代理店にとって、それはビデオ制作の経済学を変えます。コストや複雑さのためにビデオ広告を見送ったことがある人にとって、それは完全に障壁を取り除きます。
このモデルはCreatifyで利用可能であり、ElevenLabs、Runware、fal.aiとの統合により、AIインフラストラクチャの上で開発しようとする開発者やクリエーターにとっては、独立した機能としてますますアクセスしやすくなっています。
1枚の写真。1つの音声クリップ。スタジオで撮影したかのように見えるビデオ。












