


Creatify-Team
TEILEN



IN DIESEM ARTIKEL
Du hast ein Produktfoto, ein Moodboard-Motiv oder ein Stück Concept Art. Du willst, dass es sich bewegt. Vor fünf Jahren bedeutete das After Effects, ein 3D-Modell, einen Motion Designer und ein paar Wochen Abstimmung. Heute kannst du ein KI-Video aus einem Foto in unter einer Minute erstellen.

Aber "Bild hochladen, Video bekommen" vereinfacht stark, was hier passiert. Die Qualität deines Outputs hängt davon ab, mit welchem Bild du startest, wie du das Modell promptest und welches Tool du auswählst. Dieser Leitfaden zeigt dir, wie du ein Video mit KI end-to-end erstellst, damit du Videos aus Bildern generieren kannst, die in echten Kampagnen bestehen und nicht nur in einem Demo-Reel cool aussehen.
Was KI-Bild-zu-Video-Generierung ist (und wie sie funktioniert)
Wenn du KI nutzt, um ein Bild in Video umzuwandeln, analysiert das Modell dein Standbild auf Komposition, Tiefe, Beleuchtung und räumliche Struktur. Anschließend prognostiziert es plausible Bewegung Frame für Frame und erzeugt neue Pixel, die im ursprünglichen Bild nicht existierten.
Stell es dir vor wie einen Kameramann, der ein Foto betrachtet und sich vorstellt, was passieren würde, wenn sich die Kamera zu bewegen beginnt.

Die KI schätzt Tiefe ab (was vorne ist, was hinten liegt), leitet Physik ab (wie Stoff fällt, wie Wasser fließt) und rendert diese Vorhersagen als aufeinanderfolgende Frames, die zu einem kurzen Clip zusammengeführt werden.
Die meisten Systeme nutzen Diffusions-Transformer-Architekturen, um das zu bewältigen. Das Modell startet mit Rauschen und verfeinert es iterativ zu kohärenten Frames, konditioniert auf dein Quellbild und jeden Text-Prompt, den du eingibst.
Das Ergebnis ist typischerweise ein Clip von 3 bis 10 Sekunden. Das ist weniger eine Einschränkung der Tools als vielmehr eine Reflexion der Funktionsweise der Technologie: Je weiter du dich vom ursprünglichen Frame entfernst, desto mehr muss das Modell erfinden, und desto höher ist das Risiko visueller Artefakte.
Warum das für Marketer und Creator wichtig ist
Zu lernen, wie man aus Fotos ein Video erstellt, erforderte früher Motion-Graphics-Software, Stockfootage-Bibliotheken oder ein Produktionsteam. Das machte Video zu einem Engpass für alle ohne dediziertes Kreativteam.
KI-Bild-zu-Video beseitigt diesen Engpass für bestimmte Use Cases. Produkt-Hero-Shots können zu animierten Promos werden. Concept Art kann in Storyboard-Animatics verwandelt werden. Ein einzelnes Lifestyle-Foto kann scroll-stoppenden Social Content erzeugen.
Große Plattformen haben diese Fähigkeit direkt in ihre Ökosysteme integriert. Adobe Firefly bietet Bild-zu-Video als Teil seiner Creative Suite an. Google Vids enthält jetzt Veo-gestützte Bild-zu-Video-Generierung für Workspace-Nutzer. Und dedizierte KI-Ad-Plattformen wie Creatify geben Marketern Zugriff auf 30+ Videomodelle (Veo 3, Kling, Seedance, MiniMax Hailuo, Wan und andere) in einem einzigen Asset Generator, mit der Möglichkeit, von einem Produktbild in Minuten zu einer fertigen Videoanzeige zu gelangen.

Der Wandel hat weniger mit Neuheit als mit Produktionsökonomie zu tun. Wenn das Generieren eines Videos aus einem Foto Centbeträge kostet und Sekunden statt 1.000+ $ und Wochen braucht, ändert sich die Rechnung dafür, wie viele kreative Varianten du testen kannst.
Wie du das richtige Foto auswählst, um aus einem Bild ein Video zu generieren
Die Qualität deines KI-Videos aus einem Foto hängt stark davon ab, was du dem Modell fütterst. Hier ist, was am besten funktioniert.
Starke Komposition mit einem klaren Motiv. Das Modell muss verstehen, was in der Szene ist, bevor es sie animieren kann. Ein sauberes Produktfoto vor einem einfachen Hintergrund gibt der KI weit mehr Spielraum als ein überladenes Lifestyle-Foto mit 15 konkurrierenden Elementen.
Sichtbare Tiefenhinweise. Fotos mit natürlicher Trennung von Vordergrund, Mittelgrund und Hintergrund erzeugen überzeugendere Bewegung. Die KI nutzt diese Hinweise, um Parallax-Effekte und Kamerabewegungen zu erzeugen, die dreidimensional wirken.
Gute Auflösung und Kontrast. Unscharfe, schlecht beleuchtete oder stark komprimierte Bilder zwingen das Modell, Details zu erraten, was oft zu matschigen oder artefaktbehafteten Ergebnissen führt. Starte mit der schärfsten Version deines Bildes, die du hast.
Angedeutete Bewegung hilft. Ein Foto eines Models im Schritt, fließender Stoff oder spritzendes Wasser gibt der KI einen natürlichen Ausgangspunkt für Bewegung. Statische, perfekt symmetrische Kompositionen können zu subtiler, wenig interessanter Bewegung führen.
Eine praktische Faustregel: Wenn ein menschlicher Fotograf dein Bild ansehen und sofort beschreiben könnte, was als Nächstes passieren würde, kann die KI daraus wahrscheinlich überzeugende Bewegung erzeugen. Wenn die Szene mehrdeutig oder abstrakt ist, rechne mit mehr Versuch und Irrtum.

Schritt-für-Schritt-Workflow, um Video aus Bildern zu erstellen
1. Bereite dein Quellbild vor

Wähle oder erstelle ein Bild, das die obigen Kriterien erfüllt. Wenn du mit Produktfotos arbeitest, nimm die höchstauflösende verfügbare Version. Für E-Commerce-Verkäufer, die nur vom Hersteller bereitgestellte Bilder haben, können Tools wie Creatifys Asset Generator Produktvisuals zuerst verbessern oder neu generieren, bevor sie sie in Video umwandeln.

2. Definiere dein Endergebnis
Unterschiedliche Ziele erfordern unterschiedliche Ansätze:
Produkt-Motion-Ad: Du willst, dass sich das Produkt dreht, schwebt oder in einem gestylten Umfeld mit subtiler Kamerabewegung erscheint.
Cinematic B-Roll: Du willst atmosphärische Bewegung wie vorbeiziehende Wolken, wechselndes Licht oder einen langsamen Dolly-Push.
AI-Art-Animation: Du willst stilisierte, kreative Bewegung, bei der visuelles Interesse vor Realismus steht.
Social-Media-Clip: Du willst auffällige Bewegung, optimiert für vertikales Scrollen.

3. Schreibe deinen Motion-Prompt
Die meisten Bild-zu-Video-Tools akzeptieren einen Text-Prompt, der beschreibt, welche Bewegung du willst. Hier lassen die meisten Leute Qualität liegen (mehr zum Prompten unten).
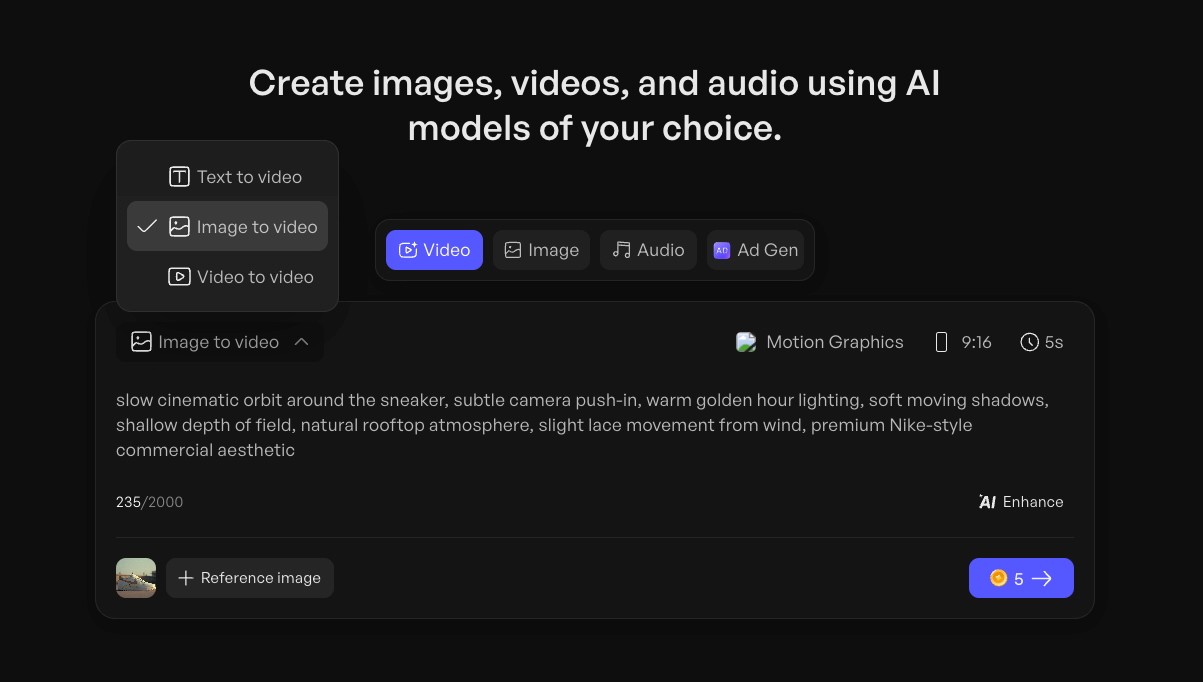
4. Wähle die Ausgabe-Einstellungen
Lege vor dem Generieren dein Seitenverhältnis fest (9:16 für Stories und Reels, 16:9 für YouTube, 1:1 für Feed-Posts), die Dauer und die Auflösung. Das nachträgliche Ändern bedeutet meist, alles von Grund auf neu zu generieren.

5. Generieren, prüfen, iterieren
Generiere den Clip, schau ihn in voller Auflösung an und entscheide, ob die Bewegung deiner Absicht entspricht. Die meisten Workflows brauchen 2 bis 4 Iterationen, um bei einer funktionierenden Version anzukommen. Wenn sich die Bewegung falsch anfühlt, passe deinen Prompt vor dem erneuten Generieren an, statt zu versuchen, es im Post zu reparieren.
6. Exportieren und ausspielen
Lade im Ziel-Format herunter (MP4 ist der universelle Standard) und spiele es auf deiner Anzeigenplattform oder deinem Content-Kanal aus. Wenn du bezahlte Kampagnen fährst, generiere mehrere Varianten mit unterschiedlichen Bewegungsstilen, um zu testen, welche am besten performt.
Lies auch: Wie man 2026 ein Produktvideo erstellt (kein Studio nötig)
Wie du bessere Motion-Prompts schreibst, wenn du ein KI-Video aus einem Foto erstellst
Prompting ist die Hebelwirkung stärkste Fähigkeit in der KI-Video-Generierung. Ein vager Prompt erzeugt vage Bewegung. Ein spezifischer Prompt erzeugt absichtsvolle, nutzbare Ergebnisse.
Beschreibe das Kameraverhalten, nicht das Gefühl. "Cinematic" sagt dem Modell fast nichts. "Langsamer Push-in von der Halbnahen zur Nahaufnahme über 5 Sekunden" gibt ihm eine konkrete Anweisung, die es ausführen kann.
Nutze räumliche und zeitliche Sprache. Gib Richtung an (links nach rechts, von oben nach unten, zur Kamera hin), Geschwindigkeit (langsam, gleichmäßig, allmählich) und Dauer. Je präziser du die Bewegung beschreibst, desto näher entspricht das Ergebnis deiner Absicht.
Begrenze die Komplexität der Bewegung. Nach einem sanften Zoom auf ein Produkt zu fragen funktioniert gut. Zu verlangen, dass eine Person läuft, während die Kamera kreist und sich der Hintergrund von Tag zu Nacht verändert, wird wahrscheinlich Artefakte erzeugen. Ein oder zwei Bewegungselemente pro Clip sind derzeit der Sweet Spot für aktuelle Modelle.
Beschreibe Atmosphäre, nicht Emotion. "Warmes Nachmittagslicht mit einer sanften Brise, die die Vorhänge bewegt" ist umsetzbar. "Lass es gemütlich und einladend wirken" ist es nicht.
Hier ist ein Vergleich:
Schwacher Prompt: "Mach aus diesem Produktfoto ein cooles Video"
Starker Prompt: "Langsamer Zoom auf das Produkt aus leicht erhöhter Perspektive. Sanfte Studio-Beleuchtung mit einer leichten Schattenverschiebung von links nach rechts. Hintergrund bleibt statisch. 5 Sekunden, 9:16-Seitenverhältnis."
Der starke Prompt spezifiziert Kamerabewegung, Lichtverhalten, was sich bewegen soll und was nicht, Dauer und Format. Genau dieses Detailniveau trennt nutzbare Ergebnisse von vergeudetem Generierungsguthaben.

Kreative Anwendungsfälle
E-Commerce-Produktanzeigen. Verwandle statische Katalogbilder in animierte Produkt-Showcases, ganz ohne Fotoshooting. Besonders nützlich, um mehrere visuelle Ansätze in großem Maßstab zu testen. Alibaba-Verkäufer, die die Plattformintegration von Creatify nutzten, erzeugten in 3 Monaten über 200.000 Videoanzeigen, die meisten ausgehend von Produktbildern.
Social-Media-Content. Verwandle Moodboard-Bilder, Behind-the-Scenes-Fotos oder Marken-Assets in kurze Clips für Stories, Reels oder TikTok. Bewegung performt in scrollbasierten Feeds naturgemäß besser als statische Bilder.
Pre-Production und Storyboarding. Animate Concept Art oder Standortfotos, um grobe Animatics zu erstellen, bevor du dich auf einen vollständigen Produktions-Dreh festlegst. Das ist in Agentur-Workflows immer verbreiteter, in denen Kunden die "Vision sehen" müssen, bevor sie ein Budget freigeben.
Präsentationen und Pitch-Decks. Verwandle Produkt-Mockups oder Datenvisualisierungen in kurze Motion-Clips, die Aufmerksamkeit besser halten als statische Slides. Google Vids unterstützt diesen Workflow nativ für Workspace-Nutzer.
KI-Art und kreatives Experimentieren. Für Creator, die lernen wollen, wie man KI-Art-Videos erstellt, eröffnet Bild-zu-Video Bewegung aus Illustrationen, digitalen Gemälden oder KI-generierten Bildern. Das Ergebnis ist oft visuell interessanter als Text-zu-Video, weil du dem Modell einen reicheren Ausgangspunkt gibst.

Was du von der Ausgabequalität erwarten kannst (und häufige Fehler)
Realistische Erwartungen
Aktuelle Bild-zu-Video-Modelle erzeugen kurze Clips, keine vollständigen Szenen. Erwarte 3 bis 10 Sekunden Bewegung, die sich gut für Inserts, Loops, Social Clips und Anzeigenvarianten eignet. Die Technologie ist stark bei Produktbewegungen, atmosphärischem B-Roll und stilisierter Bewegung. Schwächer ist sie bei komplexer menschlicher Bewegung, Szenen mit mehreren Personen und präziser Physiksimulation.
Die Ausgabequalität variiert je nach Modell. Zum Beispiel liefern in Creatifys Asset Generator Veo 3 und Kling 3.0 Pro tendenziell fotorealistischere Ergebnisse, während Seedance und MiniMax Hailuo stärker zu dynamischer, stilisierter Bewegung tendieren. Dasselbe Bild über 2 bis 3 Modelle zu testen, ist der schnellste Weg herauszufinden, was für deinen konkreten Use Case funktioniert. Ein paar verschiedene Aufnahmen zu einer kohärenten Videoanzeige zu kombinieren, ist oft ein großartiger Ansatz.
Lies auch: Die 6 leistungsstärksten KI-Video-Generierungs-APIs im Jahr 2026
Häufige Fehler
Mit einem schlechten Bild zu starten. Fotos mit niedriger Auflösung, Unschärfe oder starker Komprimierung erzeugen unabhängig vom Modell minderwertiges Video. Müll rein, Müll raus.
Den Prompt zu überladen. Das Anfordern von fünf gleichzeitigen Bewegungselementen in einem einzigen Clip überfordert das Modell. Bleib pro Generierung bei ein oder zwei Bewegungsarten.
Seitenverhältnis und Format zu ignorieren. Einen 16:9-Clip zu generieren, wenn du für Instagram 9:16 brauchst, verschwendet einen Generierungsdurchlauf. Lege deine Ausgabespezifikationen fest, bevor du auf Generieren klickst.
Narratives Video von einem einzelnen Bild zu erwarten. Bild-zu-Video glänzt bei Bewegung und Atmosphäre, nicht beim Storytelling. Wenn du einen narrativen Bogen brauchst, brauchst du eine Abfolge von Clips, nicht eine einzelne Generierung aus einem Foto.

Ethik, Offenlegung und Provenienz
KI-generiertes Video wirft berechtigte Fragen nach der Authentizität von Inhalten auf, besonders bei markenbezogenen oder öffentlich sichtbaren Inhalten. Die Leitlinien des NIST zu synthetischen Inhalten betonen Provenienz-Tracking, Metadaten und Wasserzeichen als praktische Maßnahmen zur Risikominderung.
Für Marketer ist die praktische Schlussfolgerung klar: Weisen Sie darauf hin, wenn Inhalte KI-generiert sind, falls Ihre Plattform oder Branche das verlangt, führen Sie klare interne Aufzeichnungen darüber, welche Assets KI-produziert sind, und vermeiden Sie den Einsatz von KI-generiertem Video in Kontexten, in denen es irreführend sein könnte (wie gefälschten Testimonials oder erfundenen Demonstrationen).
Die FTC ist zunehmend aktiv bei der Prüfung KI-generierter Marketinginhalte. Den Offenlegungsnormen voraus zu sein, schützt deine Marke, selbst wenn bestimmte Vorschriften noch nicht nachgezogen haben.
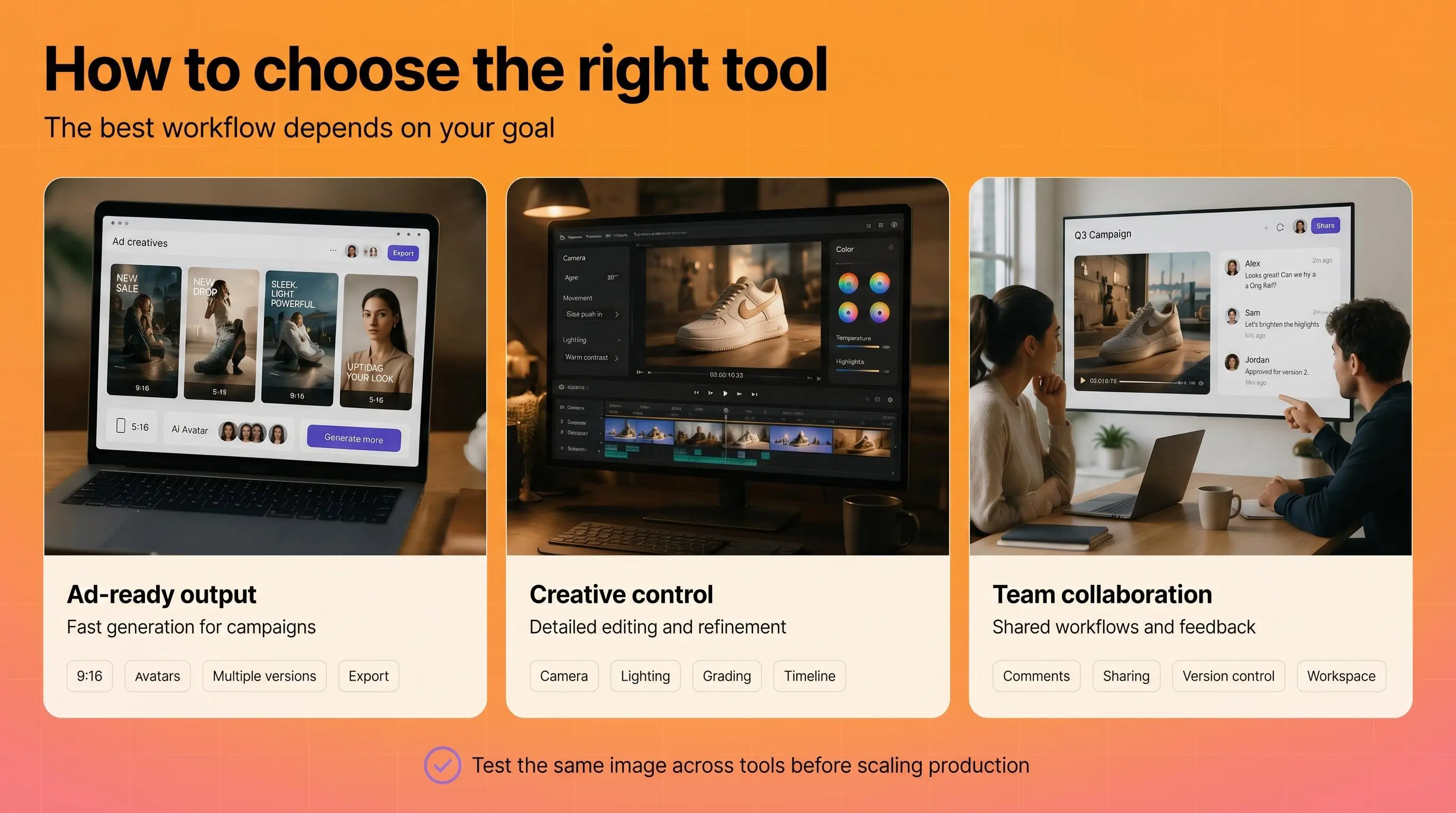
Wie du das richtige Tool auswählst
Das richtige Tool, um aus Fotos ein Video zu erstellen, hängt davon ab, worauf du optimierst.
Wenn du schnell ad-taugliche Ergebnisse brauchst, suche nach Plattformen, die Bild-zu-Video-Generierung mit ad-spezifischen Features wie Skripterstellung, Avatar-Integration, Seitenverhältnis-Presets und Plattform-Export kombinieren. Creatifys Asset Generator passt hier, mit 30+ Bild- und Video-KI-Modellen, Ein-Klick-Konvertierung von generierten Bildern in Videos und der Möglichkeit, Outputs direkt in Ad-Kampagnen über Meta, TikTok, YouTube und AppLovin einzuspeisen.

Wenn du redaktionelle oder kreative Kontrolle brauchst, Adobe Fireflys Bild-zu-Video integriert sich in das breitere Creative-Cloud-Ökosystem und gibt dir granularere Kontrolle über Kamerabewegung, Beleuchtung und Postproduktion.
Wenn du in einem Team-Kollaborations-Workflow arbeitest, Google Vids mit Veo bringt Bild-zu-Video in die Workspace-Umgebung, in der dein Team bereits arbeitet.
Unabhängig davon, welches Tool du wählst, teste es zuerst mit demselben Bild, bevor du dich festlegst. Generiere einen Clip aus deinem stärksten Produktfoto oder Markenbild und bewerte Bewegungskonsistenz, Auflösung und wie viel Prompt-Iteration nötig ist, um etwas Nutzbares zu erhalten. Das beste Tool ist dasjenige, das konstant Ergebnisse liefert, hinter die du Mediabudget stellen würdest.
Häufig gestellte Fragen
Wie erstelle ich mit KI ein Video aus einem einzelnen Foto?
Lade dein Foto in ein KI-Bild-zu-Video-Tool hoch, füge einen Text-Prompt hinzu, der die gewünschte Bewegung beschreibt, lege dein Ausgabeformat fest (Seitenverhältnis, Dauer) und generiere. Die meisten Tools erzeugen in unter einer Minute einen 3- bis 10-Sekunden-Clip. Rechne mit 2 bis 4 Iterationen, um die Bewegung zu verfeinern.
Welche Fotos eignen sich am besten für die KI-Video-Generierung?
Hochauflösende Bilder mit einem klaren Motiv, sichtbaren Tiefenhinweisen und gutem Kontrast liefern die besten Ergebnisse. Vermeide überladene Kompositionen, unscharfe Bilder oder stark komprimierte Dateien. Fotos mit angedeuteter Bewegung (fließender Stoff, Posen mitten in der Aktion) geben der KI einen natürlichen Ausgangspunkt.
Kann ich Videos aus Bildern für kommerzielle Nutzung generieren?
Ja, die meisten KI-Video-Plattformen gewähren kommerzielle Nutzungsrechte für Inhalte, die du erzeugst. Prüfe die spezifischen Nutzungsbedingungen des Tools, das du verwendest. Für Kampagnen beinhalten Plattformen wie Creatify kommerzielle Rechte in allen kostenpflichtigen Plänen.
Wie lang sind KI-generierte Videos aus Fotos?
Typischerweise 3 bis 10 Sekunden pro Generierung. Einige Tools unterstützen bis zu 15 oder 20 Sekunden. Für längere Inhalte musst du mehrere Clips generieren und zusammen schneiden oder ein Tool mit Multi-Szenen-Workflow-Funktionen nutzen.
Wie erstelle ich KI-Art-Videos aus Illustrationen oder digitaler Kunst?
Der Workflow ist derselbe wie bei Fotos: Lade deine Illustration hoch, schreibe einen Motion-Prompt und generiere. Stiliserte und illustrierte Bilder erzeugen oft visuell interessantere KI-Art-Videos, weil das Modell bei nicht-fotorealistischen Inhalten mehr kreative Freiheit hat.
Was ist der Unterschied zwischen Bild-zu-Video und Text-zu-Video-KI?
Bild-zu-Video startet mit einem konkreten visuellen Ausgangspunkt und fügt Bewegung hinzu. Text-zu-Video erzeugt sowohl die Visuals als auch die Bewegung allein aus einer Textbeschreibung. Bild-zu-Video liefert in der Regel konsistentere, vorhersehbarere Ergebnisse, weil das Modell mit einer konkreten visuellen Referenz arbeitet.
Muss ich offenlegen, dass mein Video KI-generiert wurde?
Die Offenlegungspflichten hängen von deiner Plattform und Branche ab. Die FTC prüft KI-generierte Marketinginhalte stärker, und NIST empfiehlt Provenienz-Tracking für synthetische Medien. Best Practice: Offenlegen, wenn es verlangt ist, und unabhängig davon interne Aufzeichnungen über KI-generierte Assets führen.
Wie viele Video-Varianten sollte ich aus einem Foto generieren?
Für Kampagnen ist das Testen von 5 bis 10 Varianten mit unterschiedlichen Bewegungsstilen, Kamerawinkeln und Tempi ein starker Ausgangspunkt. Die Kosten pro Generierung sind auf den meisten Plattformen niedrig genug, dass der begrenzende Faktor deine Testkapazität ist, nicht das Produktionsbudget.
Du hast ein Produktfoto, ein Moodboard-Motiv oder ein Stück Concept Art. Du willst, dass es sich bewegt. Vor fünf Jahren bedeutete das After Effects, ein 3D-Modell, einen Motion Designer und ein paar Wochen Abstimmung. Heute kannst du ein KI-Video aus einem Foto in unter einer Minute erstellen.
Aber "Bild hochladen, Video bekommen" vereinfacht stark, was hier passiert. Die Qualität deines Outputs hängt davon ab, mit welchem Bild du startest, wie du das Modell promptest und welches Tool du auswählst. Dieser Leitfaden zeigt dir, wie du ein Video mit KI end-to-end erstellst, damit du Videos aus Bildern generieren kannst, die in echten Kampagnen bestehen und nicht nur in einem Demo-Reel cool aussehen.
Was KI-Bild-zu-Video-Generierung ist (und wie sie funktioniert)
Wenn du KI nutzt, um ein Bild in Video umzuwandeln, analysiert das Modell dein Standbild auf Komposition, Tiefe, Beleuchtung und räumliche Struktur. Anschließend prognostiziert es plausible Bewegung Frame für Frame und erzeugt neue Pixel, die im ursprünglichen Bild nicht existierten.
Stell es dir vor wie einen Kameramann, der ein Foto betrachtet und sich vorstellt, was passieren würde, wenn sich die Kamera zu bewegen beginnt.
Die KI schätzt Tiefe ab (was vorne ist, was hinten liegt), leitet Physik ab (wie Stoff fällt, wie Wasser fließt) und rendert diese Vorhersagen als aufeinanderfolgende Frames, die zu einem kurzen Clip zusammengeführt werden.
Die meisten Systeme nutzen Diffusions-Transformer-Architekturen, um das zu bewältigen. Das Modell startet mit Rauschen und verfeinert es iterativ zu kohärenten Frames, konditioniert auf dein Quellbild und jeden Text-Prompt, den du eingibst.
Das Ergebnis ist typischerweise ein Clip von 3 bis 10 Sekunden. Das ist weniger eine Einschränkung der Tools als vielmehr eine Reflexion der Funktionsweise der Technologie: Je weiter du dich vom ursprünglichen Frame entfernst, desto mehr muss das Modell erfinden, und desto höher ist das Risiko visueller Artefakte.
Warum das für Marketer und Creator wichtig ist
Zu lernen, wie man aus Fotos ein Video erstellt, erforderte früher Motion-Graphics-Software, Stockfootage-Bibliotheken oder ein Produktionsteam. Das machte Video zu einem Engpass für alle ohne dediziertes Kreativteam.
KI-Bild-zu-Video beseitigt diesen Engpass für bestimmte Use Cases. Produkt-Hero-Shots können zu animierten Promos werden. Concept Art kann in Storyboard-Animatics verwandelt werden. Ein einzelnes Lifestyle-Foto kann scroll-stoppenden Social Content erzeugen.
Große Plattformen haben diese Fähigkeit direkt in ihre Ökosysteme integriert. Adobe Firefly bietet Bild-zu-Video als Teil seiner Creative Suite an. Google Vids enthält jetzt Veo-gestützte Bild-zu-Video-Generierung für Workspace-Nutzer. Und dedizierte KI-Ad-Plattformen wie Creatify geben Marketern Zugriff auf 30+ Videomodelle (Veo 3, Kling, Seedance, MiniMax Hailuo, Wan und andere) in einem einzigen Asset Generator, mit der Möglichkeit, von einem Produktbild in Minuten zu einer fertigen Videoanzeige zu gelangen.
Der Wandel hat weniger mit Neuheit als mit Produktionsökonomie zu tun. Wenn das Generieren eines Videos aus einem Foto Centbeträge kostet und Sekunden statt 1.000+ $ und Wochen braucht, ändert sich die Rechnung dafür, wie viele kreative Varianten du testen kannst.
Wie du das richtige Foto auswählst, um aus einem Bild ein Video zu generieren
Die Qualität deines KI-Videos aus einem Foto hängt stark davon ab, was du dem Modell fütterst. Hier ist, was am besten funktioniert.
Starke Komposition mit einem klaren Motiv. Das Modell muss verstehen, was in der Szene ist, bevor es sie animieren kann. Ein sauberes Produktfoto vor einem einfachen Hintergrund gibt der KI weit mehr Spielraum als ein überladenes Lifestyle-Foto mit 15 konkurrierenden Elementen.
Sichtbare Tiefenhinweise. Fotos mit natürlicher Trennung von Vordergrund, Mittelgrund und Hintergrund erzeugen überzeugendere Bewegung. Die KI nutzt diese Hinweise, um Parallax-Effekte und Kamerabewegungen zu erzeugen, die dreidimensional wirken.
Gute Auflösung und Kontrast. Unscharfe, schlecht beleuchtete oder stark komprimierte Bilder zwingen das Modell, Details zu erraten, was oft zu matschigen oder artefaktbehafteten Ergebnissen führt. Starte mit der schärfsten Version deines Bildes, die du hast.
Angedeutete Bewegung hilft. Ein Foto eines Models im Schritt, fließender Stoff oder spritzendes Wasser gibt der KI einen natürlichen Ausgangspunkt für Bewegung. Statische, perfekt symmetrische Kompositionen können zu subtiler, wenig interessanter Bewegung führen.
Eine praktische Faustregel: Wenn ein menschlicher Fotograf dein Bild ansehen und sofort beschreiben könnte, was als Nächstes passieren würde, kann die KI daraus wahrscheinlich überzeugende Bewegung erzeugen. Wenn die Szene mehrdeutig oder abstrakt ist, rechne mit mehr Versuch und Irrtum.
Schritt-für-Schritt-Workflow, um Video aus Bildern zu erstellen
1. Bereite dein Quellbild vor
Wähle oder erstelle ein Bild, das die obigen Kriterien erfüllt. Wenn du mit Produktfotos arbeitest, nimm die höchstauflösende verfügbare Version. Für E-Commerce-Verkäufer, die nur vom Hersteller bereitgestellte Bilder haben, können Tools wie Creatifys Asset Generator Produktvisuals zuerst verbessern oder neu generieren, bevor sie sie in Video umwandeln.
2. Definiere dein Endergebnis
Unterschiedliche Ziele erfordern unterschiedliche Ansätze:
Produkt-Motion-Ad: Du willst, dass sich das Produkt dreht, schwebt oder in einem gestylten Umfeld mit subtiler Kamerabewegung erscheint.
Cinematic B-Roll: Du willst atmosphärische Bewegung wie vorbeiziehende Wolken, wechselndes Licht oder einen langsamen Dolly-Push.
AI-Art-Animation: Du willst stilisierte, kreative Bewegung, bei der visuelles Interesse vor Realismus steht.
Social-Media-Clip: Du willst auffällige Bewegung, optimiert für vertikales Scrollen.
3. Schreibe deinen Motion-Prompt
Die meisten Bild-zu-Video-Tools akzeptieren einen Text-Prompt, der beschreibt, welche Bewegung du willst. Hier lassen die meisten Leute Qualität liegen (mehr zum Prompten unten).
4. Wähle die Ausgabe-Einstellungen
Lege vor dem Generieren dein Seitenverhältnis fest (9:16 für Stories und Reels, 16:9 für YouTube, 1:1 für Feed-Posts), die Dauer und die Auflösung. Das nachträgliche Ändern bedeutet meist, alles von Grund auf neu zu generieren.
5. Generieren, prüfen, iterieren
Generiere den Clip, schau ihn in voller Auflösung an und entscheide, ob die Bewegung deiner Absicht entspricht. Die meisten Workflows brauchen 2 bis 4 Iterationen, um bei einer funktionierenden Version anzukommen. Wenn sich die Bewegung falsch anfühlt, passe deinen Prompt vor dem erneuten Generieren an, statt zu versuchen, es im Post zu reparieren.
6. Exportieren und ausspielen
Lade im Ziel-Format herunter (MP4 ist der universelle Standard) und spiele es auf deiner Anzeigenplattform oder deinem Content-Kanal aus. Wenn du bezahlte Kampagnen fährst, generiere mehrere Varianten mit unterschiedlichen Bewegungsstilen, um zu testen, welche am besten performt.
Lies auch: Wie man 2026 ein Produktvideo erstellt (kein Studio nötig)
Wie du bessere Motion-Prompts schreibst, wenn du ein KI-Video aus einem Foto erstellst
Prompting ist die Hebelwirkung stärkste Fähigkeit in der KI-Video-Generierung. Ein vager Prompt erzeugt vage Bewegung. Ein spezifischer Prompt erzeugt absichtsvolle, nutzbare Ergebnisse.
Beschreibe das Kameraverhalten, nicht das Gefühl. "Cinematic" sagt dem Modell fast nichts. "Langsamer Push-in von der Halbnahen zur Nahaufnahme über 5 Sekunden" gibt ihm eine konkrete Anweisung, die es ausführen kann.
Nutze räumliche und zeitliche Sprache. Gib Richtung an (links nach rechts, von oben nach unten, zur Kamera hin), Geschwindigkeit (langsam, gleichmäßig, allmählich) und Dauer. Je präziser du die Bewegung beschreibst, desto näher entspricht das Ergebnis deiner Absicht.
Begrenze die Komplexität der Bewegung. Nach einem sanften Zoom auf ein Produkt zu fragen funktioniert gut. Zu verlangen, dass eine Person läuft, während die Kamera kreist und sich der Hintergrund von Tag zu Nacht verändert, wird wahrscheinlich Artefakte erzeugen. Ein oder zwei Bewegungselemente pro Clip sind derzeit der Sweet Spot für aktuelle Modelle.
Beschreibe Atmosphäre, nicht Emotion. "Warmes Nachmittagslicht mit einer sanften Brise, die die Vorhänge bewegt" ist umsetzbar. "Lass es gemütlich und einladend wirken" ist es nicht.
Hier ist ein Vergleich:
Schwacher Prompt: "Mach aus diesem Produktfoto ein cooles Video"
Starker Prompt: "Langsamer Zoom auf das Produkt aus leicht erhöhter Perspektive. Sanfte Studio-Beleuchtung mit einer leichten Schattenverschiebung von links nach rechts. Hintergrund bleibt statisch. 5 Sekunden, 9:16-Seitenverhältnis."
Der starke Prompt spezifiziert Kamerabewegung, Lichtverhalten, was sich bewegen soll und was nicht, Dauer und Format. Genau dieses Detailniveau trennt nutzbare Ergebnisse von vergeudetem Generierungsguthaben.
Kreative Anwendungsfälle
E-Commerce-Produktanzeigen. Verwandle statische Katalogbilder in animierte Produkt-Showcases, ganz ohne Fotoshooting. Besonders nützlich, um mehrere visuelle Ansätze in großem Maßstab zu testen. Alibaba-Verkäufer, die die Plattformintegration von Creatify nutzten, erzeugten in 3 Monaten über 200.000 Videoanzeigen, die meisten ausgehend von Produktbildern.
Social-Media-Content. Verwandle Moodboard-Bilder, Behind-the-Scenes-Fotos oder Marken-Assets in kurze Clips für Stories, Reels oder TikTok. Bewegung performt in scrollbasierten Feeds naturgemäß besser als statische Bilder.
Pre-Production und Storyboarding. Animate Concept Art oder Standortfotos, um grobe Animatics zu erstellen, bevor du dich auf einen vollständigen Produktions-Dreh festlegst. Das ist in Agentur-Workflows immer verbreiteter, in denen Kunden die "Vision sehen" müssen, bevor sie ein Budget freigeben.
Präsentationen und Pitch-Decks. Verwandle Produkt-Mockups oder Datenvisualisierungen in kurze Motion-Clips, die Aufmerksamkeit besser halten als statische Slides. Google Vids unterstützt diesen Workflow nativ für Workspace-Nutzer.
KI-Art und kreatives Experimentieren. Für Creator, die lernen wollen, wie man KI-Art-Videos erstellt, eröffnet Bild-zu-Video Bewegung aus Illustrationen, digitalen Gemälden oder KI-generierten Bildern. Das Ergebnis ist oft visuell interessanter als Text-zu-Video, weil du dem Modell einen reicheren Ausgangspunkt gibst.
Was du von der Ausgabequalität erwarten kannst (und häufige Fehler)
Realistische Erwartungen
Aktuelle Bild-zu-Video-Modelle erzeugen kurze Clips, keine vollständigen Szenen. Erwarte 3 bis 10 Sekunden Bewegung, die sich gut für Inserts, Loops, Social Clips und Anzeigenvarianten eignet. Die Technologie ist stark bei Produktbewegungen, atmosphärischem B-Roll und stilisierter Bewegung. Schwächer ist sie bei komplexer menschlicher Bewegung, Szenen mit mehreren Personen und präziser Physiksimulation.
Die Ausgabequalität variiert je nach Modell. Zum Beispiel liefern in Creatifys Asset Generator Veo 3 und Kling 3.0 Pro tendenziell fotorealistischere Ergebnisse, während Seedance und MiniMax Hailuo stärker zu dynamischer, stilisierter Bewegung tendieren. Dasselbe Bild über 2 bis 3 Modelle zu testen, ist der schnellste Weg herauszufinden, was für deinen konkreten Use Case funktioniert. Ein paar verschiedene Aufnahmen zu einer kohärenten Videoanzeige zu kombinieren, ist oft ein großartiger Ansatz.
Lies auch: Die 6 leistungsstärksten KI-Video-Generierungs-APIs im Jahr 2026
Häufige Fehler
Mit einem schlechten Bild zu starten. Fotos mit niedriger Auflösung, Unschärfe oder starker Komprimierung erzeugen unabhängig vom Modell minderwertiges Video. Müll rein, Müll raus.
Den Prompt zu überladen. Das Anfordern von fünf gleichzeitigen Bewegungselementen in einem einzigen Clip überfordert das Modell. Bleib pro Generierung bei ein oder zwei Bewegungsarten.
Seitenverhältnis und Format zu ignorieren. Einen 16:9-Clip zu generieren, wenn du für Instagram 9:16 brauchst, verschwendet einen Generierungsdurchlauf. Lege deine Ausgabespezifikationen fest, bevor du auf Generieren klickst.
Narratives Video von einem einzelnen Bild zu erwarten. Bild-zu-Video glänzt bei Bewegung und Atmosphäre, nicht beim Storytelling. Wenn du einen narrativen Bogen brauchst, brauchst du eine Abfolge von Clips, nicht eine einzelne Generierung aus einem Foto.
Ethik, Offenlegung und Provenienz
KI-generiertes Video wirft berechtigte Fragen nach der Authentizität von Inhalten auf, besonders bei markenbezogenen oder öffentlich sichtbaren Inhalten. Die Leitlinien des NIST zu synthetischen Inhalten betonen Provenienz-Tracking, Metadaten und Wasserzeichen als praktische Maßnahmen zur Risikominderung.
Für Marketer ist die praktische Schlussfolgerung klar: Weisen Sie darauf hin, wenn Inhalte KI-generiert sind, falls Ihre Plattform oder Branche das verlangt, führen Sie klare interne Aufzeichnungen darüber, welche Assets KI-produziert sind, und vermeiden Sie den Einsatz von KI-generiertem Video in Kontexten, in denen es irreführend sein könnte (wie gefälschten Testimonials oder erfundenen Demonstrationen).
Die FTC ist zunehmend aktiv bei der Prüfung KI-generierter Marketinginhalte. Den Offenlegungsnormen voraus zu sein, schützt deine Marke, selbst wenn bestimmte Vorschriften noch nicht nachgezogen haben.
Wie du das richtige Tool auswählst
Das richtige Tool, um aus Fotos ein Video zu erstellen, hängt davon ab, worauf du optimierst.
Wenn du schnell ad-taugliche Ergebnisse brauchst, suche nach Plattformen, die Bild-zu-Video-Generierung mit ad-spezifischen Features wie Skripterstellung, Avatar-Integration, Seitenverhältnis-Presets und Plattform-Export kombinieren. Creatifys Asset Generator passt hier, mit 30+ Bild- und Video-KI-Modellen, Ein-Klick-Konvertierung von generierten Bildern in Videos und der Möglichkeit, Outputs direkt in Ad-Kampagnen über Meta, TikTok, YouTube und AppLovin einzuspeisen.
Wenn du redaktionelle oder kreative Kontrolle brauchst, Adobe Fireflys Bild-zu-Video integriert sich in das breitere Creative-Cloud-Ökosystem und gibt dir granularere Kontrolle über Kamerabewegung, Beleuchtung und Postproduktion.
Wenn du in einem Team-Kollaborations-Workflow arbeitest, Google Vids mit Veo bringt Bild-zu-Video in die Workspace-Umgebung, in der dein Team bereits arbeitet.
Unabhängig davon, welches Tool du wählst, teste es zuerst mit demselben Bild, bevor du dich festlegst. Generiere einen Clip aus deinem stärksten Produktfoto oder Markenbild und bewerte Bewegungskonsistenz, Auflösung und wie viel Prompt-Iteration nötig ist, um etwas Nutzbares zu erhalten. Das beste Tool ist dasjenige, das konstant Ergebnisse liefert, hinter die du Mediabudget stellen würdest.
Häufig gestellte Fragen
Wie erstelle ich mit KI ein Video aus einem einzelnen Foto?
Lade dein Foto in ein KI-Bild-zu-Video-Tool hoch, füge einen Text-Prompt hinzu, der die gewünschte Bewegung beschreibt, lege dein Ausgabeformat fest (Seitenverhältnis, Dauer) und generiere. Die meisten Tools erzeugen in unter einer Minute einen 3- bis 10-Sekunden-Clip. Rechne mit 2 bis 4 Iterationen, um die Bewegung zu verfeinern.
Welche Fotos eignen sich am besten für die KI-Video-Generierung?
Hochauflösende Bilder mit einem klaren Motiv, sichtbaren Tiefenhinweisen und gutem Kontrast liefern die besten Ergebnisse. Vermeide überladene Kompositionen, unscharfe Bilder oder stark komprimierte Dateien. Fotos mit angedeuteter Bewegung (fließender Stoff, Posen mitten in der Aktion) geben der KI einen natürlichen Ausgangspunkt.
Kann ich Videos aus Bildern für kommerzielle Nutzung generieren?
Ja, die meisten KI-Video-Plattformen gewähren kommerzielle Nutzungsrechte für Inhalte, die du erzeugst. Prüfe die spezifischen Nutzungsbedingungen des Tools, das du verwendest. Für Kampagnen beinhalten Plattformen wie Creatify kommerzielle Rechte in allen kostenpflichtigen Plänen.
Wie lang sind KI-generierte Videos aus Fotos?
Typischerweise 3 bis 10 Sekunden pro Generierung. Einige Tools unterstützen bis zu 15 oder 20 Sekunden. Für längere Inhalte musst du mehrere Clips generieren und zusammen schneiden oder ein Tool mit Multi-Szenen-Workflow-Funktionen nutzen.
Wie erstelle ich KI-Art-Videos aus Illustrationen oder digitaler Kunst?
Der Workflow ist derselbe wie bei Fotos: Lade deine Illustration hoch, schreibe einen Motion-Prompt und generiere. Stiliserte und illustrierte Bilder erzeugen oft visuell interessantere KI-Art-Videos, weil das Modell bei nicht-fotorealistischen Inhalten mehr kreative Freiheit hat.
Was ist der Unterschied zwischen Bild-zu-Video und Text-zu-Video-KI?
Bild-zu-Video startet mit einem konkreten visuellen Ausgangspunkt und fügt Bewegung hinzu. Text-zu-Video erzeugt sowohl die Visuals als auch die Bewegung allein aus einer Textbeschreibung. Bild-zu-Video liefert in der Regel konsistentere, vorhersehbarere Ergebnisse, weil das Modell mit einer konkreten visuellen Referenz arbeitet.
Muss ich offenlegen, dass mein Video KI-generiert wurde?
Die Offenlegungspflichten hängen von deiner Plattform und Branche ab. Die FTC prüft KI-generierte Marketinginhalte stärker, und NIST empfiehlt Provenienz-Tracking für synthetische Medien. Best Practice: Offenlegen, wenn es verlangt ist, und unabhängig davon interne Aufzeichnungen über KI-generierte Assets führen.
Wie viele Video-Varianten sollte ich aus einem Foto generieren?
Für Kampagnen ist das Testen von 5 bis 10 Varianten mit unterschiedlichen Bewegungsstilen, Kamerawinkeln und Tempi ein starker Ausgangspunkt. Die Kosten pro Generierung sind auf den meisten Plattformen niedrig genug, dass der begrenzende Faktor deine Testkapazität ist, nicht das Produktionsbudget.

Bereit, Ihr Produkt in ein fesselndes Video zu verwandeln?











