


Creatify 团队
分享



在本文中
大多数人工智能视频生成器给你的都是诡异的谷歌谷中——嘴巴在动,眼睛不动,身体像纸板剪影一样僵硬不动。Aurora 的构建旨在解决这个问题。

Aurora是 Creatify 的专有扩散变换器(DiT)模型,用于音频驱动的化身合成。只需给它一张照片和音频片段,它就能生成那个人说话、演示或唱歌的工作室级视频,具有同步的面部表情、自然的眼睛运动、呼吸和完整的上半身动作。这不仅仅是对口型同步,它是一场完整的表演。
该模型已被集成到ElevenLabs、 Runware和fal.ai中,成为首批视频生成模型之一,这标志着AI视频生成的方向。
本指南涵盖如何从中获得最佳效果。
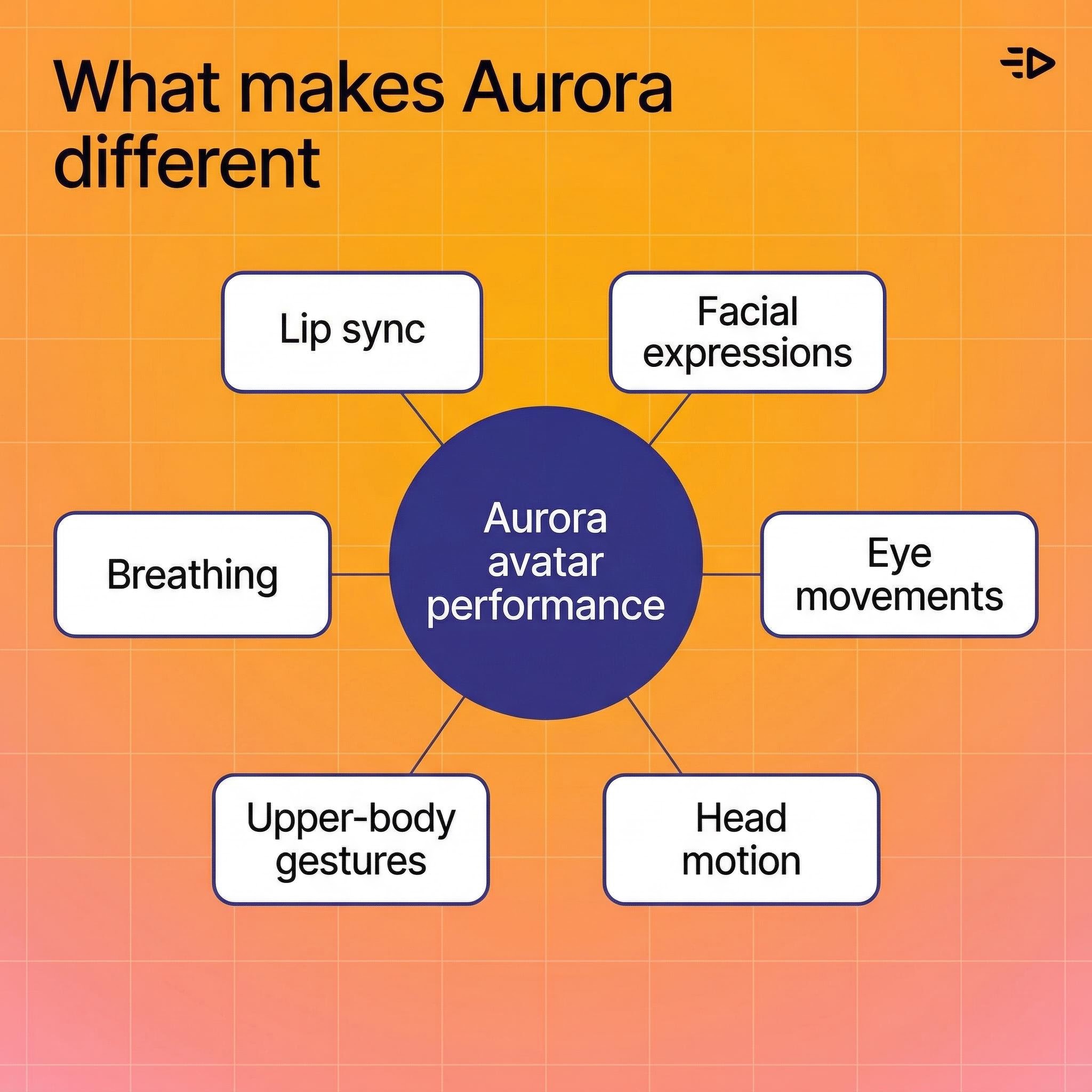
是什么让 Aurora 与众不同
大多数说话头工具仅仅动画化嘴巴就算完成,而 Aurora 将化身视为一个整体人物,树立了AI 视频生成的现实主义新标杆。
以下是该模型实际产生的效果:
口型同步精确跟踪音频,包括不同音素的细微嘴形
面部表情匹配声调和情感表达
眼球运动——眨眼、目光转移、自然聚焦
头部动作——点头、倾斜、细微的姿势变化
上半身手势——手部动作、肩膀偏移,使说话头像看起来更真实而非机械化的自然运动
呼吸——句间的胸部运动
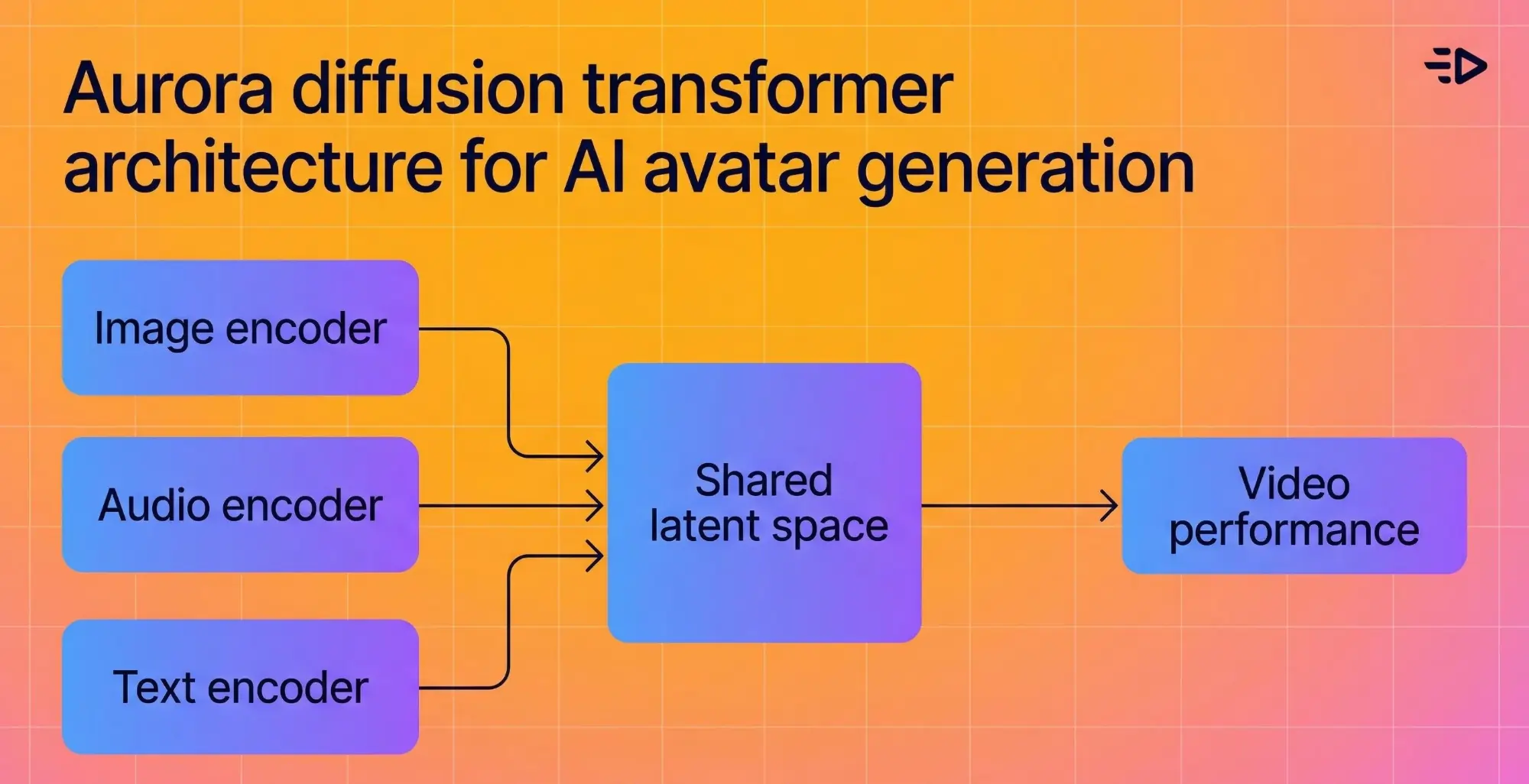
底层架构将图像编码器、文本编码器和音频编码器融合到共享的延迟空间中,使模型理解所说内容的情感背景,并在视觉上反映出来。如果音频听起来很热情,化身看起来也很热情。
你可以用它创建什么

Aurora 支持的内容类型超越了简单的说话头像,成为AI视频生成工作流程的强大工具:
产品演示——显示代言人持产品,指出并解释其优点。适用于护肤、科技、消费品等。
UGC 风格广告——自拍形式,轻微手持摄像机抖动,随意的交付。难以与真实创作者内容区分。
播客片段——化身稍微侧面向,像是在和共同主持人交谈,带有投入、对话性的神情。
多语言内容——无需重新拍摄即可生成任何语言版本的视频。Aurora 保持化身的唇部动作与新音频同步。
唱歌的化身——给它专辑封面和一首歌,化身就会表演出来。用于音乐营销或娱乐内容。
动画角色——不仅适用于逼真的照片,也可用于插画角色和风格化艺术。
利用 AI 视频生成取得最佳效果
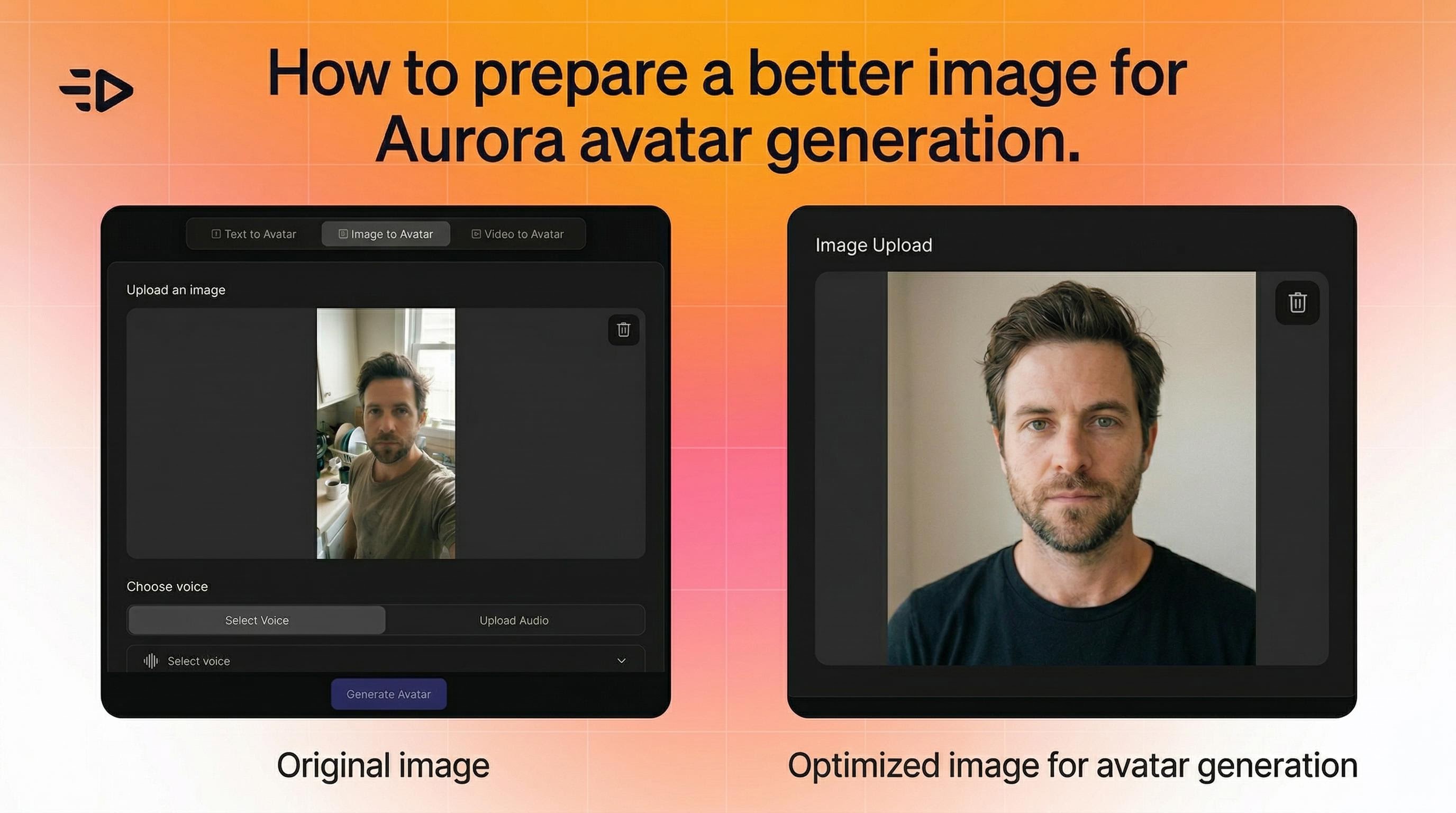
1. 从合适的图像开始
Aurora 灵活可变——可与照片、渲染图和角色艺术一起使用。但有一些有助于优化的要素:
主体应在画面中清晰可见且易于区分
对于一致的多场景视频,所有图像保持类似构图(例如,所有人像拍摄)
如果动作看起来不自然,尝试使用更清晰、更中性姿势的图像
在角度、照明或构图方面没有严格限制。Aurora 动态调整。
2. 使用 Voice Model V3
这是确保质量效果的必选项。Voice Model V3 提供最精确的口型同步和最广泛的表现范围。旧版语音模型的输出明显较差。
保持语速适中清晰。如果同步感觉稍有偏差,稍慢语速通常可修正。句子间添加自然停顿,让化身有呼吸空间,使表演更加人性化。
3. 掌握你的提示
这是大多数人浪费效果的地方。提示告诉 Aurora 化身应如何表现——不仅仅是外观,还有动作、传达的情感,以及如何与场景互动。
这是你任何标准说话头视频的基础提示:
4K 工作室采访,中近景(肩部以上裁剪)。浅灰色无缝背景,均匀柔和的主光——无光线变化。主持人面向镜头,稳定的眼神接触。双手保持框外,身体完全静止。超高清晰度。
从那里,再加入特有的行为提示,具体到你的使用案例。
按格式的提示示例:
使用场景 | 增加的行为提示 |
|---|---|
产品演示 | 持产品的人向镜头展示标签,同时进行解释,时不时地指向它。 |
自然说话头 | 与镜头直接自然交流的人,伴随呼吸的胸部运动。自然的解释手势和眼神动作。 |
播客 | 面对一侧,看起来像是在与该方向的人交谈,表现出对话题的兴趣的投入表情。 |
UGC 自拍 | 镜头前手未能见的人讲话。摄像机有轻微的抖动,如同手持。 |
热情的产品评论 | 人用手热情地移动,试图解释产品的优点。 |
越详细说明情感和身体行为,效果越好。模糊的提示产生普通的结果。
专业提示:使用 GPT 将基础电影设置与具体的使用案例结合。提示:“为 [X] 产品演示生成最佳 Aurora 提示”,它会自动将技术框架与正确的行为提示混合。
4. 调整 prompt_guidance
Aurora 具有prompt_guidance参数,范围从0到4。它控制模型遵循提示的严格程度与允许自然变化的程度。
大多数场景从1开始。它给模型空间自然表演,同时仍然遵循指示。
增加它如果化身偏离提示或不遵照你设置的行为提示。
减少它如果表现感觉僵硬或机械。
5. 情感匹配音频、图像和提示
最常见的错误:使用充满活力、欢快的音轨搭配中性面孔图像和冷静的行为提示。模型将这三种输入融合在一起。如果它们在不同方向拖动,输出就会觉得不一致。
如果你的音频充满活力,你的提示应该要求活跃、富有表现力的行为。如果它是冷静和信息性的,你的提示应反映这种风格。这三种输入越一致,结果就越令人信服。
快速故障排除
问题 | 解决方法 |
|---|---|
口型同步感觉有偏差 | 稍微放慢语速 |
动作看起来不自然 | 尝试使用姿势更清晰的不同图像 |
化身偏离提示 | 增加 prompt_guidance |
表现感觉过于机械 | 降低 prompt_guidance;添加更柔和的行为提示 |
场景间不一致 | 使用具有类似构图和风格的图像 |

更大的图景
Aurora 在 AI 视频生成中代表了一步重要的发展——不仅因为它是新奇工具,而是因为它解决了实际的制作问题。创建高质量的化身视频曾需摄像机、工作室、表演者和后期制作工作流程。现在只需一张照片和一个脚本。
对于运营付费广告的效果营销人员,这改变了创意测试的计算方式。对于管理多个客户的代理商来说,这改变了视频制作的经济效益。对于以前因成本或复杂性而放弃视频广告的人来说,这完全消除了这些障碍。
该模型已在 Creatify 上线,与 ElevenLabs、Runware 和fal.ai的集成意味着它作为开发者和创作者在 AI 基础设施之上构建的独立功能正变得越来越普及。
一张照片。一个音频片段。一段看起来像是在工作室拍摄的视频。
大多数人工智能视频生成器给你的都是诡异的谷歌谷中——嘴巴在动,眼睛不动,身体像纸板剪影一样僵硬不动。Aurora 的构建旨在解决这个问题。
Aurora是 Creatify 的专有扩散变换器(DiT)模型,用于音频驱动的化身合成。只需给它一张照片和音频片段,它就能生成那个人说话、演示或唱歌的工作室级视频,具有同步的面部表情、自然的眼睛运动、呼吸和完整的上半身动作。这不仅仅是对口型同步,它是一场完整的表演。
该模型已被集成到ElevenLabs、 Runware和fal.ai中,成为首批视频生成模型之一,这标志着AI视频生成的方向。
本指南涵盖如何从中获得最佳效果。
是什么让 Aurora 与众不同
大多数说话头工具仅仅动画化嘴巴就算完成,而 Aurora 将化身视为一个整体人物,树立了AI 视频生成的现实主义新标杆。
以下是该模型实际产生的效果:
口型同步精确跟踪音频,包括不同音素的细微嘴形
面部表情匹配声调和情感表达
眼球运动——眨眼、目光转移、自然聚焦
头部动作——点头、倾斜、细微的姿势变化
上半身手势——手部动作、肩膀偏移,使说话头像看起来更真实而非机械化的自然运动
呼吸——句间的胸部运动
底层架构将图像编码器、文本编码器和音频编码器融合到共享的延迟空间中,使模型理解所说内容的情感背景,并在视觉上反映出来。如果音频听起来很热情,化身看起来也很热情。
你可以用它创建什么
Aurora 支持的内容类型超越了简单的说话头像,成为AI视频生成工作流程的强大工具:
产品演示——显示代言人持产品,指出并解释其优点。适用于护肤、科技、消费品等。
UGC 风格广告——自拍形式,轻微手持摄像机抖动,随意的交付。难以与真实创作者内容区分。
播客片段——化身稍微侧面向,像是在和共同主持人交谈,带有投入、对话性的神情。
多语言内容——无需重新拍摄即可生成任何语言版本的视频。Aurora 保持化身的唇部动作与新音频同步。
唱歌的化身——给它专辑封面和一首歌,化身就会表演出来。用于音乐营销或娱乐内容。
动画角色——不仅适用于逼真的照片,也可用于插画角色和风格化艺术。
利用 AI 视频生成取得最佳效果
1. 从合适的图像开始
Aurora 灵活可变——可与照片、渲染图和角色艺术一起使用。但有一些有助于优化的要素:
主体应在画面中清晰可见且易于区分
对于一致的多场景视频,所有图像保持类似构图(例如,所有人像拍摄)
如果动作看起来不自然,尝试使用更清晰、更中性姿势的图像
在角度、照明或构图方面没有严格限制。Aurora 动态调整。
2. 使用 Voice Model V3
这是确保质量效果的必选项。Voice Model V3 提供最精确的口型同步和最广泛的表现范围。旧版语音模型的输出明显较差。
保持语速适中清晰。如果同步感觉稍有偏差,稍慢语速通常可修正。句子间添加自然停顿,让化身有呼吸空间,使表演更加人性化。
3. 掌握你的提示
这是大多数人浪费效果的地方。提示告诉 Aurora 化身应如何表现——不仅仅是外观,还有动作、传达的情感,以及如何与场景互动。
这是你任何标准说话头视频的基础提示:
4K 工作室采访,中近景(肩部以上裁剪)。浅灰色无缝背景,均匀柔和的主光——无光线变化。主持人面向镜头,稳定的眼神接触。双手保持框外,身体完全静止。超高清晰度。
从那里,再加入特有的行为提示,具体到你的使用案例。
按格式的提示示例:
使用场景 | 增加的行为提示 |
|---|---|
产品演示 | 持产品的人向镜头展示标签,同时进行解释,时不时地指向它。 |
自然说话头 | 与镜头直接自然交流的人,伴随呼吸的胸部运动。自然的解释手势和眼神动作。 |
播客 | 面对一侧,看起来像是在与该方向的人交谈,表现出对话题的兴趣的投入表情。 |
UGC 自拍 | 镜头前手未能见的人讲话。摄像机有轻微的抖动,如同手持。 |
热情的产品评论 | 人用手热情地移动,试图解释产品的优点。 |
越详细说明情感和身体行为,效果越好。模糊的提示产生普通的结果。
专业提示:使用 GPT 将基础电影设置与具体的使用案例结合。提示:“为 [X] 产品演示生成最佳 Aurora 提示”,它会自动将技术框架与正确的行为提示混合。
4. 调整 prompt_guidance
Aurora 具有prompt_guidance参数,范围从0到4。它控制模型遵循提示的严格程度与允许自然变化的程度。
大多数场景从1开始。它给模型空间自然表演,同时仍然遵循指示。
增加它如果化身偏离提示或不遵照你设置的行为提示。
减少它如果表现感觉僵硬或机械。
5. 情感匹配音频、图像和提示
最常见的错误:使用充满活力、欢快的音轨搭配中性面孔图像和冷静的行为提示。模型将这三种输入融合在一起。如果它们在不同方向拖动,输出就会觉得不一致。
如果你的音频充满活力,你的提示应该要求活跃、富有表现力的行为。如果它是冷静和信息性的,你的提示应反映这种风格。这三种输入越一致,结果就越令人信服。
快速故障排除
问题 | 解决方法 |
|---|---|
口型同步感觉有偏差 | 稍微放慢语速 |
动作看起来不自然 | 尝试使用姿势更清晰的不同图像 |
化身偏离提示 | 增加 prompt_guidance |
表现感觉过于机械 | 降低 prompt_guidance;添加更柔和的行为提示 |
场景间不一致 | 使用具有类似构图和风格的图像 |
更大的图景
Aurora 在 AI 视频生成中代表了一步重要的发展——不仅因为它是新奇工具,而是因为它解决了实际的制作问题。创建高质量的化身视频曾需摄像机、工作室、表演者和后期制作工作流程。现在只需一张照片和一个脚本。
对于运营付费广告的效果营销人员,这改变了创意测试的计算方式。对于管理多个客户的代理商来说,这改变了视频制作的经济效益。对于以前因成本或复杂性而放弃视频广告的人来说,这完全消除了这些障碍。
该模型已在 Creatify 上线,与 ElevenLabs、Runware 和fal.ai的集成意味着它作为开发者和创作者在 AI 基础设施之上构建的独立功能正变得越来越普及。
一张照片。一个音频片段。一段看起来像是在工作室拍摄的视频。












