


Creatify-Team
TEILEN



IN DIESEM ARTIKEL
Die meisten KI-Videogeneratoren geben Ihnen das unheimliche Tal - Münder, die sich bewegen, Augen, die es nicht tun, Körper, die wie ein Pappaufsteller eingefroren bleiben. Aurora wurde entwickelt, um das zu beheben.

Aurora ist Creatifys firmeneigenes Diffusion Transformer (DiT) Modell für audio-gesteuerte Avatar-Synthese. Geben Sie ihm ein Foto und einen Audioclip, und es generiert ein Studio-Qualitätsvideo dieser Person, die spricht, präsentiert oder singt - mit synchronisierten Gesichtsausdrücken, natürlichen Augenbewegungen, Atmung und vollständigen Oberkörpergesten. Es ist nicht nur Lippen-Synchronisation. Es ist eine vollständige Performance.
Das Modell wurde bereits in ElevenLabs, Runware und fal.ai integriert als eines der ersten Video-Generierungsmodelle - ein Signal dafür, wohin die KI-Video-Generierung steuert.
Dieser Leitfaden beschreibt, wie man die besten Ergebnisse daraus erzielt.
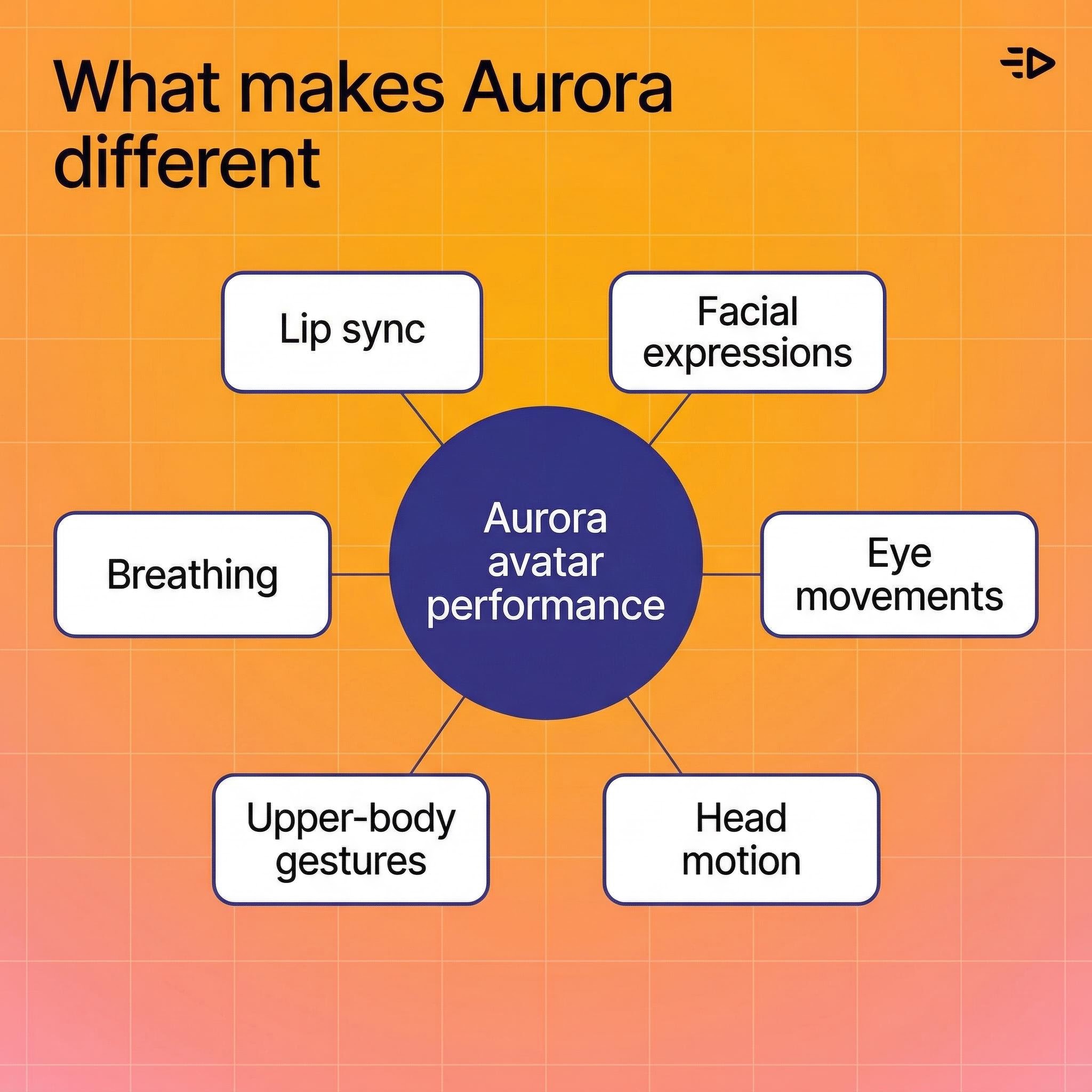
Was Aurora anders macht
Die meisten Talking-Head-Tools animieren den Mund und sind damit fertig. Aurora behandelt den Avatar als eine ganze Person und setzt einen neuen Maßstab für realistische KI-Video-Generierung.
Hier ist, was das Modell tatsächlich produziert:
Lippen-Synchronisation, die das Audio genau verfolgt, einschließlich subtiler Mundformen für verschiedene Phoneme
Gesichtsausdrücke, die zur vokalen Tonlage und emotionalen Darbietung passen
Augenbewegungen - Blinzeln, Blickwechsel, natürlicher Fokus
Kopfbewegung - Nicken, Neigen, subtile Positionsänderungen
Oberkörpergesten - Handbewegungen, Schulterverlagerungen, die Art von natürlicher Bewegung, die einen Talking Head real statt robotisch wirken lässt
Atmung - Brustbewegungen zwischen den Sätzen
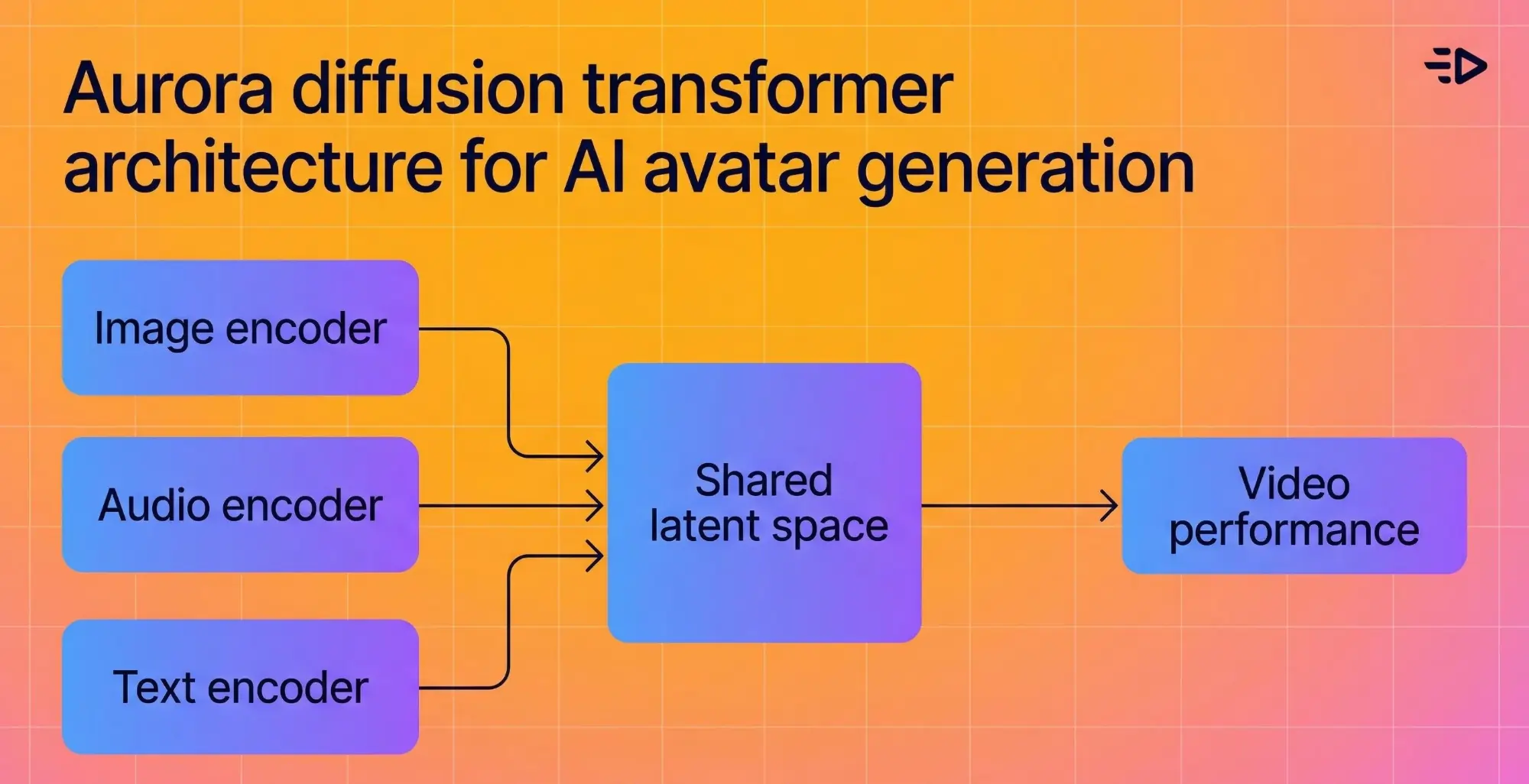
Die zugrunde liegende Architektur verbindet einen Bild-Encoder, Text-Encoder und Audio-Encoder in einem gemeinsamen latenten Raum, sodass das Modell den emotionalen Kontext dessen, was gesagt wird, versteht und visuell wiedergibt. Wenn das Audio enthusiastisch klingt, sieht der Avatar enthusiastisch aus.
Was Sie damit bauen können

Aurora unterstützt eine breite Palette von Inhaltstypen über einfache Talking Heads hinaus und macht es zu einem leistungsstarken Werkzeug für KI-Video-Gen-Workflows:
Produktdemos - Zeigen Sie eine Person, die ein Produkt hält, darauf zeigt und dessen Vorteile erklärt. Funktioniert für Hautpflege, Technik, Konsumgüter, alles.
UGC-style Anzeigen - Selfie-Format, leichte Handkamerabeben, lässige Darstellung. Schwer von echtem Creator-Content zu unterscheiden.
Podcast-Clips - Der Avatar schaut leicht zur Seite, als ob er mit einem Co-Moderator spricht, mit einem engagierten, gesprächigen Ausdruck.
Mehrsprachige Inhalte - Erzeugen Sie dasselbe Video in jeder Sprache ohne erneutes Filmen. Aurora hält die Lippenbewegungen des Avatars synchron mit dem neuen Audio.
Singing Avatars - Geben Sie ihnen Albumcover und ein Lied, und der Avatar führt es auf. Nützlich für Musikmarketing oder Unterhaltung.
Animierte Charaktere - Funktioniert mit illustrierten Charakteren und stilisierter Kunst, nicht nur mit realistischen Fotos.
Die besten Ergebnisse mit AI-Video-Gen erzielen
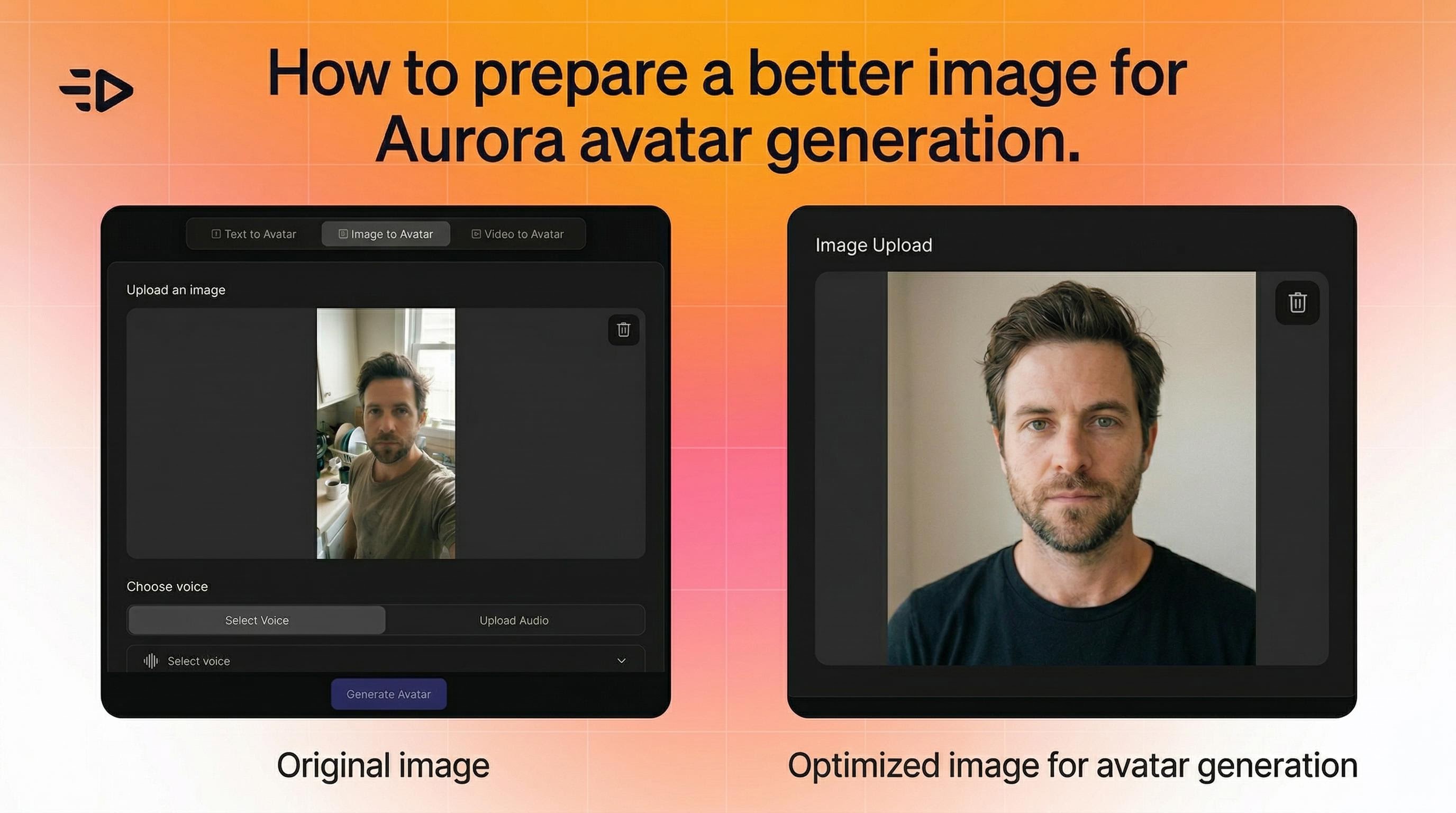
1. Beginnen Sie mit dem richtigen Bild
Aurora ist flexibel - es funktioniert mit Fotos, Renderings und Charakterbildern. Aber ein paar Dinge helfen:
Das Motiv sollte deutlich sichtbar und im Bild erkennbar sein
Für konsistente Mehrszenen-Videos, behalten Sie ähnliche Bildausschnitte in allen Bildern bei (z.B. alle Portraitaufnahmen)
Wenn die Bewegung unnatürlich aussieht, versuchen Sie ein Bild mit einer klareren, neutraleren Pose
Es gibt keine strikten Einschränkungen hinsichtlich Winkel, Beleuchtung oder Komposition. Aurora passt sich dynamisch an.
2. Verwenden Sie Voice Model V3
Das ist nicht verhandelbar für qualitativ hochwertige Ergebnisse. Voice Model V3 liefert den genauesten Lippen-Sync und das breiteste expressive Spektrum. Ältere Sprachmodelle liefern merklich schlechtere Ergebnisse.
Halten Sie die Sprachgeschwindigkeit moderat und klar. Wenn die Synchronisation leicht daneben liegt, hilft es normalerweise, die Stimme leicht zu verlangsamen. Fügen Sie natürliche Pausen zwischen den Sätzen ein - sie geben dem Avatar Raum zum Atmen und machen die Darbietung menschlicher.
3. Beherrschen Sie Ihren Prompt
Hier lassen die meisten Leute Chancen ungenutzt. Der Prompt sagt Aurora, wie sich der Avatar verhalten soll - nicht nur, wie er aussieht, sondern wie er sich bewegt, welche Emotion er vermittelt und wie er mit der Szene interagiert.
Verwenden Sie dies als Basis-Prompt für jedes Standard-Talking-Head-Video:
4K Studio-Interview, Mittelaufnahme (Schulter-hoher Ausschnitt). Solider hellgrauer nahtloser Hintergrund, gleichmäßiges sanftes Hauptlicht - keine Lichtwechsel. Der Moderator blickt in die Linse, stabiler Augenkontakt. Hände bleiben unterhalb des Rahmens, Körper absolut still. Ultrafokussiert.
Von dort aus fügen Sie verhaltensspezifische Hinweise für Ihren Anwendungsfall hinzu.
Beispiel-Prompts nach Format:
Anwendungsfall | Hinzugefügter Verhaltens-Prompt |
|---|---|
Produktdemo | Die Person, die das Produkt hält, zeigt das Etikett zur Kamera und erklärt es, zeigt gelegentlich darauf. |
Natürlicher Talking Head | Die Person spricht direkt und natürlich zur Kamera mit Bewegungen der Brust beim Atmen. Natürliche Erklärgestik und Augenbewegungen. |
Podcast | Die Person schaut und blickt zur Seite, als ob sie mit jemandem in dieser Richtung spricht, mit einem interessierten Gesichtsausdruck. |
UGC-Selfie | Die Person spricht vor der Kamera, eine Hand ist nicht sichtbar. Die Kamera hat leichtes Wackeln, als ob sie in der Hand gehalten wird. |
Begeisterte Produktbewertung | Die Hände der Person bewegen sich enthusiastisch, um den Vorteil des Produkts zu erklären. |
Je spezifischer Sie den emotionalen Ton und das physische Verhalten gestalten, desto besser wird das Ergebnis. Vage Prompts liefern generische Ergebnisse.
Profi-Tipp: Verwenden Sie GPT, um das grundlegende filmische Setup mit Ihrem spezifischen Anwendungsfall zu kombinieren. Geben Sie ein: "Generiere einen optimierten Aurora-Prompt für eine [X] Produktdemo", und es wird automatisch die technische Gestaltung mit den richtigen Verhaltenshinweisen kombinieren.
4. Feinabstimmung der Anweisungen
Aurora hat einen prompt_guidance Parameter, der von 0 bis 4 reicht. Er steuert, wie strikt das Modell Ihrem Prompt folgt im Vergleich zu natürlicher Variation.
Starten Sie bei 1 für die meisten Szenen. Es gibt dem Modell Raum, sich natürlich zu verhalten, während es immer noch den Anweisungen folgt.
Erhöhen Sie ihn, wenn der Avatar vom Prompt abweicht oder die von Ihnen festgelegten Verhaltenshinweise nicht befolgt.
Verringern Sie ihn, wenn die Darbietung steif oder mechanisch wirkt.
5. Passen Sie Audio, Bild und Prompt emotional an
Der häufigste Fehler: eine energetische, fröhliche Audiospur mit einem neutralen Bild und einem ruhigen Verhaltens-Prompt zu verwenden. Das Modell fusioniert alle drei Eingaben. Wenn sie in unterschiedliche Richtungen ziehen, fühlt sich das Ergebnis inkonsistent an.
Wenn Ihr Audio enthusiastisch ist, sollte Ihr Prompt nach energetischem, ausdrucksstarkem Verhalten verlangen. Wenn es ruhig und informativ ist, sollte Ihr Prompt das widerspiegeln. Je besser diese drei Eingaben aufeinander abgestimmt sind, desto überzeugender ist das Ergebnis.
Schnelle Fehlersuche
Problem | Lösung |
|---|---|
Lippensynchronisation wirkt fehlerhaft | Reduzieren Sie leicht die Sprachgeschwindigkeit |
Bewegung sieht unnatürlich aus | Versuchen Sie ein anderes Bild mit sauberer Pose |
Avatar weicht vom Prompt ab | Erhöhen Sie die Anweisungen |
Darstellung wirkt zu robotisch | Verringern Sie die Anweisungen; fügen Sie weichere Verhaltenshinweise hinzu |
Inkonsistenz zwischen Szenen | Verwenden Sie Bilder mit ähnlichem Rahmen und Stil |

Das größere Bild
Aurora stellt einen Bedeutenden Fortschritt in der KI-Video-Generierung dar - nicht weil es eine Neuheit ist, sondern weil es ein echtes Produktionsproblem löst. Hochwertige Avatar-Videos zu erstellen, erforderte früher eine Kamera, ein Studio, einen Darsteller und einen Postproduktions-Workflow. Jetzt erfordert es ein Foto und ein Skript.
Für Performance-Marketer, die bezahlte Kampagnen durchführen, ändert das die Berechnung von kreativen Tests. Für Agenturen, die mehrere Kunden verwalten, ändert sich die Wirtschaftlichkeit der Videoproduktion. Für jeden, der jemals auf Videoanzeigen verzichtet hat, weil sie zu teuer oder komplex sind, fällt die Schranke vollständig weg.
Das Modell ist live auf Creatify, und die Integration mit ElevenLabs, Runware und fal.ai bedeutet, dass es zunehmend als eigenständige Funktion für Entwickler und Kreative zugänglich ist, die auf KI-Infrastruktur aufbauen.
Ein Foto. Ein Audioclip. Ein Video, das aussieht, als hätten Sie es in einem Studio aufgenommen.
Die meisten KI-Videogeneratoren geben Ihnen das unheimliche Tal - Münder, die sich bewegen, Augen, die es nicht tun, Körper, die wie ein Pappaufsteller eingefroren bleiben. Aurora wurde entwickelt, um das zu beheben.
Aurora ist Creatifys firmeneigenes Diffusion Transformer (DiT) Modell für audio-gesteuerte Avatar-Synthese. Geben Sie ihm ein Foto und einen Audioclip, und es generiert ein Studio-Qualitätsvideo dieser Person, die spricht, präsentiert oder singt - mit synchronisierten Gesichtsausdrücken, natürlichen Augenbewegungen, Atmung und vollständigen Oberkörpergesten. Es ist nicht nur Lippen-Synchronisation. Es ist eine vollständige Performance.
Das Modell wurde bereits in ElevenLabs, Runware und fal.ai integriert als eines der ersten Video-Generierungsmodelle - ein Signal dafür, wohin die KI-Video-Generierung steuert.
Dieser Leitfaden beschreibt, wie man die besten Ergebnisse daraus erzielt.
Was Aurora anders macht
Die meisten Talking-Head-Tools animieren den Mund und sind damit fertig. Aurora behandelt den Avatar als eine ganze Person und setzt einen neuen Maßstab für realistische KI-Video-Generierung.
Hier ist, was das Modell tatsächlich produziert:
Lippen-Synchronisation, die das Audio genau verfolgt, einschließlich subtiler Mundformen für verschiedene Phoneme
Gesichtsausdrücke, die zur vokalen Tonlage und emotionalen Darbietung passen
Augenbewegungen - Blinzeln, Blickwechsel, natürlicher Fokus
Kopfbewegung - Nicken, Neigen, subtile Positionsänderungen
Oberkörpergesten - Handbewegungen, Schulterverlagerungen, die Art von natürlicher Bewegung, die einen Talking Head real statt robotisch wirken lässt
Atmung - Brustbewegungen zwischen den Sätzen
Die zugrunde liegende Architektur verbindet einen Bild-Encoder, Text-Encoder und Audio-Encoder in einem gemeinsamen latenten Raum, sodass das Modell den emotionalen Kontext dessen, was gesagt wird, versteht und visuell wiedergibt. Wenn das Audio enthusiastisch klingt, sieht der Avatar enthusiastisch aus.
Was Sie damit bauen können
Aurora unterstützt eine breite Palette von Inhaltstypen über einfache Talking Heads hinaus und macht es zu einem leistungsstarken Werkzeug für KI-Video-Gen-Workflows:
Produktdemos - Zeigen Sie eine Person, die ein Produkt hält, darauf zeigt und dessen Vorteile erklärt. Funktioniert für Hautpflege, Technik, Konsumgüter, alles.
UGC-style Anzeigen - Selfie-Format, leichte Handkamerabeben, lässige Darstellung. Schwer von echtem Creator-Content zu unterscheiden.
Podcast-Clips - Der Avatar schaut leicht zur Seite, als ob er mit einem Co-Moderator spricht, mit einem engagierten, gesprächigen Ausdruck.
Mehrsprachige Inhalte - Erzeugen Sie dasselbe Video in jeder Sprache ohne erneutes Filmen. Aurora hält die Lippenbewegungen des Avatars synchron mit dem neuen Audio.
Singing Avatars - Geben Sie ihnen Albumcover und ein Lied, und der Avatar führt es auf. Nützlich für Musikmarketing oder Unterhaltung.
Animierte Charaktere - Funktioniert mit illustrierten Charakteren und stilisierter Kunst, nicht nur mit realistischen Fotos.
Die besten Ergebnisse mit AI-Video-Gen erzielen
1. Beginnen Sie mit dem richtigen Bild
Aurora ist flexibel - es funktioniert mit Fotos, Renderings und Charakterbildern. Aber ein paar Dinge helfen:
Das Motiv sollte deutlich sichtbar und im Bild erkennbar sein
Für konsistente Mehrszenen-Videos, behalten Sie ähnliche Bildausschnitte in allen Bildern bei (z.B. alle Portraitaufnahmen)
Wenn die Bewegung unnatürlich aussieht, versuchen Sie ein Bild mit einer klareren, neutraleren Pose
Es gibt keine strikten Einschränkungen hinsichtlich Winkel, Beleuchtung oder Komposition. Aurora passt sich dynamisch an.
2. Verwenden Sie Voice Model V3
Das ist nicht verhandelbar für qualitativ hochwertige Ergebnisse. Voice Model V3 liefert den genauesten Lippen-Sync und das breiteste expressive Spektrum. Ältere Sprachmodelle liefern merklich schlechtere Ergebnisse.
Halten Sie die Sprachgeschwindigkeit moderat und klar. Wenn die Synchronisation leicht daneben liegt, hilft es normalerweise, die Stimme leicht zu verlangsamen. Fügen Sie natürliche Pausen zwischen den Sätzen ein - sie geben dem Avatar Raum zum Atmen und machen die Darbietung menschlicher.
3. Beherrschen Sie Ihren Prompt
Hier lassen die meisten Leute Chancen ungenutzt. Der Prompt sagt Aurora, wie sich der Avatar verhalten soll - nicht nur, wie er aussieht, sondern wie er sich bewegt, welche Emotion er vermittelt und wie er mit der Szene interagiert.
Verwenden Sie dies als Basis-Prompt für jedes Standard-Talking-Head-Video:
4K Studio-Interview, Mittelaufnahme (Schulter-hoher Ausschnitt). Solider hellgrauer nahtloser Hintergrund, gleichmäßiges sanftes Hauptlicht - keine Lichtwechsel. Der Moderator blickt in die Linse, stabiler Augenkontakt. Hände bleiben unterhalb des Rahmens, Körper absolut still. Ultrafokussiert.
Von dort aus fügen Sie verhaltensspezifische Hinweise für Ihren Anwendungsfall hinzu.
Beispiel-Prompts nach Format:
Anwendungsfall | Hinzugefügter Verhaltens-Prompt |
|---|---|
Produktdemo | Die Person, die das Produkt hält, zeigt das Etikett zur Kamera und erklärt es, zeigt gelegentlich darauf. |
Natürlicher Talking Head | Die Person spricht direkt und natürlich zur Kamera mit Bewegungen der Brust beim Atmen. Natürliche Erklärgestik und Augenbewegungen. |
Podcast | Die Person schaut und blickt zur Seite, als ob sie mit jemandem in dieser Richtung spricht, mit einem interessierten Gesichtsausdruck. |
UGC-Selfie | Die Person spricht vor der Kamera, eine Hand ist nicht sichtbar. Die Kamera hat leichtes Wackeln, als ob sie in der Hand gehalten wird. |
Begeisterte Produktbewertung | Die Hände der Person bewegen sich enthusiastisch, um den Vorteil des Produkts zu erklären. |
Je spezifischer Sie den emotionalen Ton und das physische Verhalten gestalten, desto besser wird das Ergebnis. Vage Prompts liefern generische Ergebnisse.
Profi-Tipp: Verwenden Sie GPT, um das grundlegende filmische Setup mit Ihrem spezifischen Anwendungsfall zu kombinieren. Geben Sie ein: "Generiere einen optimierten Aurora-Prompt für eine [X] Produktdemo", und es wird automatisch die technische Gestaltung mit den richtigen Verhaltenshinweisen kombinieren.
4. Feinabstimmung der Anweisungen
Aurora hat einen prompt_guidance Parameter, der von 0 bis 4 reicht. Er steuert, wie strikt das Modell Ihrem Prompt folgt im Vergleich zu natürlicher Variation.
Starten Sie bei 1 für die meisten Szenen. Es gibt dem Modell Raum, sich natürlich zu verhalten, während es immer noch den Anweisungen folgt.
Erhöhen Sie ihn, wenn der Avatar vom Prompt abweicht oder die von Ihnen festgelegten Verhaltenshinweise nicht befolgt.
Verringern Sie ihn, wenn die Darbietung steif oder mechanisch wirkt.
5. Passen Sie Audio, Bild und Prompt emotional an
Der häufigste Fehler: eine energetische, fröhliche Audiospur mit einem neutralen Bild und einem ruhigen Verhaltens-Prompt zu verwenden. Das Modell fusioniert alle drei Eingaben. Wenn sie in unterschiedliche Richtungen ziehen, fühlt sich das Ergebnis inkonsistent an.
Wenn Ihr Audio enthusiastisch ist, sollte Ihr Prompt nach energetischem, ausdrucksstarkem Verhalten verlangen. Wenn es ruhig und informativ ist, sollte Ihr Prompt das widerspiegeln. Je besser diese drei Eingaben aufeinander abgestimmt sind, desto überzeugender ist das Ergebnis.
Schnelle Fehlersuche
Problem | Lösung |
|---|---|
Lippensynchronisation wirkt fehlerhaft | Reduzieren Sie leicht die Sprachgeschwindigkeit |
Bewegung sieht unnatürlich aus | Versuchen Sie ein anderes Bild mit sauberer Pose |
Avatar weicht vom Prompt ab | Erhöhen Sie die Anweisungen |
Darstellung wirkt zu robotisch | Verringern Sie die Anweisungen; fügen Sie weichere Verhaltenshinweise hinzu |
Inkonsistenz zwischen Szenen | Verwenden Sie Bilder mit ähnlichem Rahmen und Stil |
Das größere Bild
Aurora stellt einen Bedeutenden Fortschritt in der KI-Video-Generierung dar - nicht weil es eine Neuheit ist, sondern weil es ein echtes Produktionsproblem löst. Hochwertige Avatar-Videos zu erstellen, erforderte früher eine Kamera, ein Studio, einen Darsteller und einen Postproduktions-Workflow. Jetzt erfordert es ein Foto und ein Skript.
Für Performance-Marketer, die bezahlte Kampagnen durchführen, ändert das die Berechnung von kreativen Tests. Für Agenturen, die mehrere Kunden verwalten, ändert sich die Wirtschaftlichkeit der Videoproduktion. Für jeden, der jemals auf Videoanzeigen verzichtet hat, weil sie zu teuer oder komplex sind, fällt die Schranke vollständig weg.
Das Modell ist live auf Creatify, und die Integration mit ElevenLabs, Runware und fal.ai bedeutet, dass es zunehmend als eigenständige Funktion für Entwickler und Kreative zugänglich ist, die auf KI-Infrastruktur aufbauen.
Ein Foto. Ein Audioclip. Ein Video, das aussieht, als hätten Sie es in einem Studio aufgenommen.

Bereit, Ihr Produkt in ein fesselndes Video zu verwandeln?











