


鲍里斯·冈察洛夫
分享



在本文中
想象一下,你重新设计一个落地页:新标题、新主视觉图、新 CTA。你做了 A/B 测试,新页面赢了,你上线了。三个月后,效果趋于平稳,而你完全不知道这三个改动里到底是哪一个带来了提升,或者它们是否真的协同发挥了作用。
这就是 A/B 测试和多变量测试之间的差距。两者都是受控实验,但回答的是不同的问题。用错方法,哪怕数据看起来很干净,你也只是盲目优化。
什么是 A/B 测试

A/B 测试将单个元素的两个版本进行对比,以确定哪个表现更好。你把受众分成两组,向每组展示一个版本,依据定义好的成功指标衡量结果,然后得出结论。
被测试的元素可以是任何东西:广告标题、CTA 按钮、落地页主视觉图、邮件主题行、优惠方案。保持不变的是,版本 A 和版本 B 之间只改变一件事。其他一切都保持一致。
这种约束正是这种方法的优势。因为只有一个变量发生变化,性能上的任何差异都可以在相当有把握的前提下归因于这一变化。它干净、易解读,而且在流量足够时,执行起来很快。
什么是多变量测试
多变量测试(有时也称为多因素测试)会同时评估多个变量,以找出哪种元素组合表现最佳。你不是测试一个标题对另一个标题,而是可以一次测试多个标题-图片-CTA 组合。
多变量测试带来的关键概念是交互效应:某个元素的影响可能取决于另一个元素的设置。某个标题与特定主视觉图搭配时,表现可能远好于与另一张图搭配,即使这个标题单独看起来并不突出。A/B 测试本身并不是为发现交互效应而设计的,不过多变量测试是这样做的,尽管实际能否检测出来仍取决于样本量和设计质量。

《NIST 工程统计手册》从实验设计的角度阐述了这种区别:单因素实验会隔离一个变量,而析因设计和多变量设计会同时估计主效应以及因素之间的交互作用。这个统计逻辑在析因和实验设计中已经非常成熟;现实中的挑战在于,更多组合意味着需要显著更多的流量和更周密的规划。
核心区别
A/B 测试 | 多变量测试 | |
|---|---|---|
测试变量 | 一个 | 同时多个 |
最佳适用场景 | 隔离测试一个改动 | 找出多个元素的最佳组合 |
所需流量 | 较低 | 显著更高 |
出结果速度 | 更快 | 更慢 |
洞察深度 | 单因素结论 | 组合与交互效应 |
复杂度 | 低 | 中到高 |
典型示例 | 标题、CTA、主题行 | 包含多个版块的落地页、包含多个创意元素的广告 |
实用总结:A/B 测试告诉你一个东西的哪个版本赢了。多变量测试告诉你多个东西的哪种组合赢了,以及这些东西是否会彼此影响。
何时使用 A/B 测试
在以下情况下,A/B 测试是正确选择:
问题很明确。 你想知道一个标题是否比另一个表现更好,或者某个 CTA 颜色是否带来更多点击。这是单因素问题,而 A/B 测试可以干净利落地回答它。
流量有限。 A/B 测试所需流量远少于多变量测试,因为你只是在两个版本之间分流。即使受众较小,也能在合理时间内产生具有统计意义的结果。
速度很重要。 A/B 测试更快达到统计显著性,因为流量只在两个版本之间集中,而不是分散到许多组合中。
你需要清晰的归因。 因为只改变一个东西,所以结果很容易解读并付诸行动。不会出现到底是哪个元素带来差异的歧义。
在实践中,大多数广告创意测试都属于这一类。测试两个切入点、两个 CTA 或两种视觉风格,本质上就是一系列 A/B 测试,而这一系列测试比试图一次测试所有东西更快地帮你建立起对有效策略的认知。

何时使用多变量测试
在以下情况下,多变量测试才值得它的复杂度:
多个元素可能存在交互。 如果你怀疑某个标题只有和特定图片搭配时才有效,或者某个 CTA 只有在特定优惠框架下才会转化,那么多变量测试是唯一能揭示这种依赖关系的方法。
流量很高。 每增加一个变量,都会成倍增加要测试的组合数。三个元素、每个都有两个版本,会产生 8 种组合。四个元素、每个都有三个版本,会产生更多组合。每个组合都需要自己的样本量来产生可靠结果,因此多变量测试只有在流量阈值足够高时才实用。
优化目标是一个包含多个独立组件的页面或活动。 当你有足够流量支撑时,包含标题、副标题、主视觉图和 CTA 区块的落地页,就是天然的多变量测试候选对象。
你想从“是什么”走向“为什么”。 A/B 测试告诉你谁赢了;多变量测试可以告诉你哪些元素推动了胜出,以及它们是否发生了交互,这能更精准地指导下一轮设计决策。

流量与样本量:关键约束
这也是大多数多变量测试出错的地方。
增加变量不只是增加复杂度,它会把流量必须分配到的单元格数量成倍放大。如果三个元素每个都有两个版本,那就是 8 种组合。每种组合都需要足够访客才能产生统计可靠的结果。如果你的日流量是 500 个会话,分到 8 种组合里,每种组合每天大约只有 60 个会话。这需要很长时间才能达到显著性,而且可能永远得不出干净的结论。
《NIST 关于选择实验设计的指南》对此有直接说明:分数析因设计可以减少所需测试组合的数量,但代价是你能够估计的交互效应会受限。流量不足,不可能获得完整的多变量洞察。设计必须匹配流量现实。
实用经验法则:如果你不确定能否在合理时间内为每种组合提供足够流量以达到显著性,那就改为顺序执行 A/B 测试。
跨渠道的 A/B 测试
A/B 测试可以自然延展到跨渠道场景。邮件主题行、广告创意、受众细分、落地页版本、CTA 文案,以及渠道专属落地页,都可以用同样的基本方法测试。
多渠道 A/B 测试的关键在于一致性:在不同渠道中衡量同一个结果指标,这样结果才具有可解释性和可比较性。如果你同时在 Meta 上测试广告创意、在邮件中测试主题行,请确保转化指标(购买、注册、试用开始)在两个实验中的定义完全一致。
一种常见的顺序方法是:先在每个渠道内运行 A/B 测试,为每个元素建立基线,然后整合跨渠道的经验,找出哪些创意和信息原则在所有渠道都适用,哪些只是渠道特定。这样比试图同时在跨渠道层面做多变量测试更有价值。
多变量活动测试
当不同受众细分可能对不同的创意、文案、优惠和版式组合产生不同反应时,多变量测试就变得很有用。你不是为所有人选一个赢家,而是在找出哪种组合最适合哪个细分人群。
这里的警告与任何多变量测试都一样:如果受众细分太小,或者活动周期太短,复杂性带来的不是清晰,而是噪音。要让某个发现可靠地成立,每个组合需要 100,000 次展示,这对一个只面向 10,000 人的活动来说毫无价值。
活动测试的正确顺序通常是这样的:先在高流量细分中做 A/B 测试,识别表现强的版本;然后在你拥有足够数据和受众规模支撑时,再用多变量测试优化组合。

统计基础:你真正测量的是什么
两种方法都是受控实验形式,并且都依赖相同的统计原则:上线前有清晰假设、定义好的核心成功指标、预先设定的显著性阈值,以及足够的样本量来检测你想要的效果。
区别在于你估计的是什么效果。A/B 测试估计主效应:改变 X 是否会产生不同结果?多变量测试同时估计主效应和交互效应:X 与 Y 结合后产生的结果,是否不同于仅有 X 或仅有 Y 时的预测?
交互效应在营销中是真实且常见的。一个折扣优惠如果用“立减 30%”来表达,可能对大多数受众都比“省 15 美元”更有效;但当它与高端品牌美学搭配时,反而可能不如后者。单独的 A/B 测试都抓不到这一点,而设计良好的多变量测试可以。
常见错误
在流量不足时运行多变量测试。 这是最常见的错误。流量被摊得太薄,组合永远达不到显著性,结果要么不明确,要么具有误导性。
一次测试太多变量。 复杂度会叠加。先从最可能带来显著差异的变量开始,而不是测试所有能测的元素。
在问题是单因素时使用多变量测试。 如果你想知道标题 A 还是标题 B 转化更好,那就是 A/B 测试。多变量测试只会增加开销,却不会增加相关洞察。
没有假设就上线测试。 没有假设的测试只是观察练习。上线前先明确你预期会发生什么,以及为什么会发生,这样结果才能验证或挑战某个具体想法。
跨渠道混用指标。 如果“转化”的定义在不同测试组或不同渠道之间不一致,结果就无法解读。上线前先锁定指标定义。
过早停止测试。 早期结果噪音很大。在某个版本刚刚领先、却还没达到统计显著性时就停止测试,是得出错误结论的最可靠方式之一。

如何选择正确的方法
按以下问题顺序思考:
你要改动多少东西? 如果只有一个,用 A/B 测试。如果有多个,可以考虑多变量测试,但前提是流量支撑得住。
你的流量够吗? 如果你无法在合理时间内为每个组合提供足够样本,那就改为顺序 A/B 测试。
你在寻找交互效应吗? 如果元素 A 是否有效取决于元素 B,那你需要多变量测试;如果不是,就不需要。
你需要多快得到答案? A/B 测试更快达到显著性。如果活动窗口很短,A/B 几乎总是更好的选择。
你真正问的问题是什么? 要具体。模糊的问题会产生无法提供有用答案的实验,不管你用哪种方法都一样。

创意产能在这里扮演什么角色
关于广告创意中的 A/B 测试和多变量测试,讨论常常卡在方法论层面。但更大的现实约束通常是制作能力:如果你只能产出 2 个创意版本,就不可能测试 10 个。
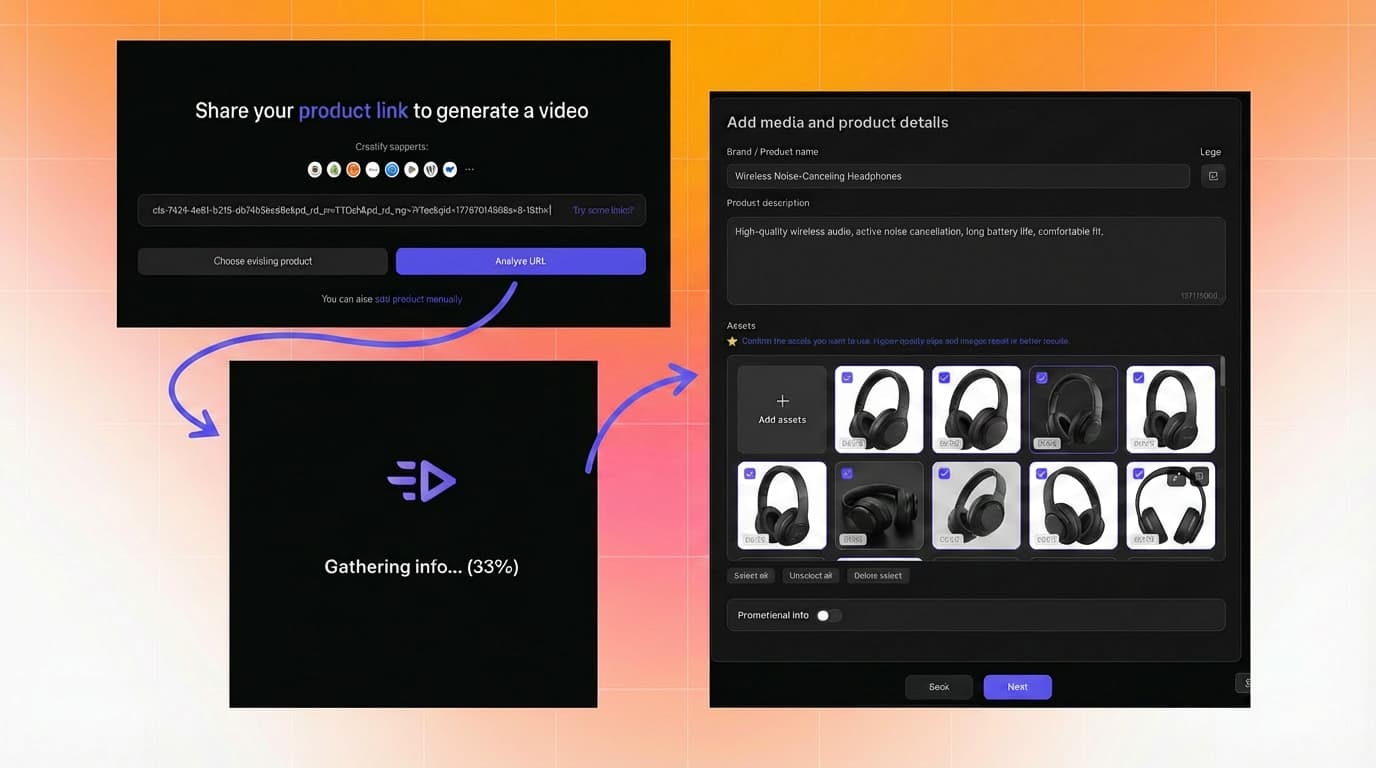
对于投放付费社媒的电商和 DTC 品牌来说,创意测试在结构上几乎总是 A/B 形式(一个切入点对另一个、一个视觉风格对另一个),但产能很重要。你能轮换的创意版本越多,你就越快学到什么有效,也越能抵御创意疲劳带来的下滑。Creatify 的 URL 转视频 和 素材生成器 工具正是为此而存在:生成足够多的创意版本,让你真正运行一套测试系统,而不是只投一两个广告就称之为测试。
LAIFE 使用 Creatify 后,每周测试的视频数量从 10 个提升到 50 个,而创意输入量的提升,直接支撑了那套测试系统,最终将他们在 TikTok 上的每单成本降到了 3.89 美元。
方法很重要,拥有足够多的创意来使用它,同样重要。
常见问题
A/B 测试和多变量测试有什么区别?
A/B 测试比较单个元素的两个版本,以确定哪个表现更好,每次只改变一个变量。多变量测试同时评估多个变量,找出哪种组合表现最佳,以及各元素之间是否存在交互。A/B 测试更简单、更快;多变量测试能提供更深入的洞察,但需要显著更多的流量。
我应该什么时候使用 A/B 测试,什么时候使用多变量测试?
当你的问题只涉及一个变量、流量有限,或者你需要快速得到结果时,用 A/B 测试。当多个元素可能相互作用、你拥有高流量,并且你需要理解是什么变量组合驱动了表现,而不只是哪个单一元素胜出时,用多变量测试。
什么是多变量定向?
多变量定向是指在不同受众细分中测试不同的创意、文案、优惠或版式组合,以识别哪种组合对每个群体表现最好。它在受众规模和活动流量足够大、能够支撑每个测试组合的有效样本量时最有效。
多变量测试需要多少流量?
没有统一阈值,但原则是每种组合都需要足够流量来达到统计显著性。变量越多,组合越多;组合越多,所需流量就越大。如果流量有限,顺序 A/B 测试通常比摊得太薄的多变量测试更可靠。
什么是多变量测试(multivariable test)?
Multivariable test 是一个非正式术语,有时与 multivariate test 互换使用。在正式统计和实验设计中,更被接受的术语是 multivariate testing,指同时评估多个变量的实验,包括它们的主效应和交互效应。这个非正式用法因行业和工具而异。
最好的多变量测试工具有哪些?
优秀的实验平台应同时支持 A/B 和多变量工作流,能够在各组合之间清晰分配流量,并提供能呈现交互效应而不仅仅是总体赢家的报告。合适的工具取决于你要测试什么:网站页面、邮件活动和广告创意各自有不同的平台要求。优先选择支持实验治理和清晰报告的工具,而不是只会替换创意版本的工具。
什么是多渠道营销中的 A/B 测试?
多渠道营销中的 A/B 测试,是指在多个渠道中同时或顺序运行受控实验,并在每个渠道使用相同的成功指标。你可以同时测试 Meta 上的广告创意、邮件主题行,以及付费搜索中的落地页版本。关键在于一致性:所有渠道使用相同的转化定义,这样结果才可比较、可解读。
我可以同时运行 A/B 测试和多变量测试吗?
可以,只要它们测试的是不同元素,或者针对不同受众细分且没有重叠。把重叠实验同时投放给同一受众,会引入混杂效应,使两个测试的结果都不可靠。
想象一下,你重新设计一个落地页:新标题、新主视觉图、新 CTA。你做了 A/B 测试,新页面赢了,你上线了。三个月后,效果趋于平稳,而你完全不知道这三个改动里到底是哪一个带来了提升,或者它们是否真的协同发挥了作用。
这就是 A/B 测试和多变量测试之间的差距。两者都是受控实验,但回答的是不同的问题。用错方法,哪怕数据看起来很干净,你也只是盲目优化。
什么是 A/B 测试
A/B 测试将单个元素的两个版本进行对比,以确定哪个表现更好。你把受众分成两组,向每组展示一个版本,依据定义好的成功指标衡量结果,然后得出结论。
被测试的元素可以是任何东西:广告标题、CTA 按钮、落地页主视觉图、邮件主题行、优惠方案。保持不变的是,版本 A 和版本 B 之间只改变一件事。其他一切都保持一致。
这种约束正是这种方法的优势。因为只有一个变量发生变化,性能上的任何差异都可以在相当有把握的前提下归因于这一变化。它干净、易解读,而且在流量足够时,执行起来很快。
什么是多变量测试
多变量测试(有时也称为多因素测试)会同时评估多个变量,以找出哪种元素组合表现最佳。你不是测试一个标题对另一个标题,而是可以一次测试多个标题-图片-CTA 组合。
多变量测试带来的关键概念是交互效应:某个元素的影响可能取决于另一个元素的设置。某个标题与特定主视觉图搭配时,表现可能远好于与另一张图搭配,即使这个标题单独看起来并不突出。A/B 测试本身并不是为发现交互效应而设计的,不过多变量测试是这样做的,尽管实际能否检测出来仍取决于样本量和设计质量。
《NIST 工程统计手册》从实验设计的角度阐述了这种区别:单因素实验会隔离一个变量,而析因设计和多变量设计会同时估计主效应以及因素之间的交互作用。这个统计逻辑在析因和实验设计中已经非常成熟;现实中的挑战在于,更多组合意味着需要显著更多的流量和更周密的规划。
核心区别
A/B 测试 | 多变量测试 | |
|---|---|---|
测试变量 | 一个 | 同时多个 |
最佳适用场景 | 隔离测试一个改动 | 找出多个元素的最佳组合 |
所需流量 | 较低 | 显著更高 |
出结果速度 | 更快 | 更慢 |
洞察深度 | 单因素结论 | 组合与交互效应 |
复杂度 | 低 | 中到高 |
典型示例 | 标题、CTA、主题行 | 包含多个版块的落地页、包含多个创意元素的广告 |
实用总结:A/B 测试告诉你一个东西的哪个版本赢了。多变量测试告诉你多个东西的哪种组合赢了,以及这些东西是否会彼此影响。
何时使用 A/B 测试
在以下情况下,A/B 测试是正确选择:
问题很明确。 你想知道一个标题是否比另一个表现更好,或者某个 CTA 颜色是否带来更多点击。这是单因素问题,而 A/B 测试可以干净利落地回答它。
流量有限。 A/B 测试所需流量远少于多变量测试,因为你只是在两个版本之间分流。即使受众较小,也能在合理时间内产生具有统计意义的结果。
速度很重要。 A/B 测试更快达到统计显著性,因为流量只在两个版本之间集中,而不是分散到许多组合中。
你需要清晰的归因。 因为只改变一个东西,所以结果很容易解读并付诸行动。不会出现到底是哪个元素带来差异的歧义。
在实践中,大多数广告创意测试都属于这一类。测试两个切入点、两个 CTA 或两种视觉风格,本质上就是一系列 A/B 测试,而这一系列测试比试图一次测试所有东西更快地帮你建立起对有效策略的认知。
何时使用多变量测试
在以下情况下,多变量测试才值得它的复杂度:
多个元素可能存在交互。 如果你怀疑某个标题只有和特定图片搭配时才有效,或者某个 CTA 只有在特定优惠框架下才会转化,那么多变量测试是唯一能揭示这种依赖关系的方法。
流量很高。 每增加一个变量,都会成倍增加要测试的组合数。三个元素、每个都有两个版本,会产生 8 种组合。四个元素、每个都有三个版本,会产生更多组合。每个组合都需要自己的样本量来产生可靠结果,因此多变量测试只有在流量阈值足够高时才实用。
优化目标是一个包含多个独立组件的页面或活动。 当你有足够流量支撑时,包含标题、副标题、主视觉图和 CTA 区块的落地页,就是天然的多变量测试候选对象。
你想从“是什么”走向“为什么”。 A/B 测试告诉你谁赢了;多变量测试可以告诉你哪些元素推动了胜出,以及它们是否发生了交互,这能更精准地指导下一轮设计决策。
流量与样本量:关键约束
这也是大多数多变量测试出错的地方。
增加变量不只是增加复杂度,它会把流量必须分配到的单元格数量成倍放大。如果三个元素每个都有两个版本,那就是 8 种组合。每种组合都需要足够访客才能产生统计可靠的结果。如果你的日流量是 500 个会话,分到 8 种组合里,每种组合每天大约只有 60 个会话。这需要很长时间才能达到显著性,而且可能永远得不出干净的结论。
《NIST 关于选择实验设计的指南》对此有直接说明:分数析因设计可以减少所需测试组合的数量,但代价是你能够估计的交互效应会受限。流量不足,不可能获得完整的多变量洞察。设计必须匹配流量现实。
实用经验法则:如果你不确定能否在合理时间内为每种组合提供足够流量以达到显著性,那就改为顺序执行 A/B 测试。
跨渠道的 A/B 测试
A/B 测试可以自然延展到跨渠道场景。邮件主题行、广告创意、受众细分、落地页版本、CTA 文案,以及渠道专属落地页,都可以用同样的基本方法测试。
多渠道 A/B 测试的关键在于一致性:在不同渠道中衡量同一个结果指标,这样结果才具有可解释性和可比较性。如果你同时在 Meta 上测试广告创意、在邮件中测试主题行,请确保转化指标(购买、注册、试用开始)在两个实验中的定义完全一致。
一种常见的顺序方法是:先在每个渠道内运行 A/B 测试,为每个元素建立基线,然后整合跨渠道的经验,找出哪些创意和信息原则在所有渠道都适用,哪些只是渠道特定。这样比试图同时在跨渠道层面做多变量测试更有价值。
多变量活动测试
当不同受众细分可能对不同的创意、文案、优惠和版式组合产生不同反应时,多变量测试就变得很有用。你不是为所有人选一个赢家,而是在找出哪种组合最适合哪个细分人群。
这里的警告与任何多变量测试都一样:如果受众细分太小,或者活动周期太短,复杂性带来的不是清晰,而是噪音。要让某个发现可靠地成立,每个组合需要 100,000 次展示,这对一个只面向 10,000 人的活动来说毫无价值。
活动测试的正确顺序通常是这样的:先在高流量细分中做 A/B 测试,识别表现强的版本;然后在你拥有足够数据和受众规模支撑时,再用多变量测试优化组合。
统计基础:你真正测量的是什么
两种方法都是受控实验形式,并且都依赖相同的统计原则:上线前有清晰假设、定义好的核心成功指标、预先设定的显著性阈值,以及足够的样本量来检测你想要的效果。
区别在于你估计的是什么效果。A/B 测试估计主效应:改变 X 是否会产生不同结果?多变量测试同时估计主效应和交互效应:X 与 Y 结合后产生的结果,是否不同于仅有 X 或仅有 Y 时的预测?
交互效应在营销中是真实且常见的。一个折扣优惠如果用“立减 30%”来表达,可能对大多数受众都比“省 15 美元”更有效;但当它与高端品牌美学搭配时,反而可能不如后者。单独的 A/B 测试都抓不到这一点,而设计良好的多变量测试可以。
常见错误
在流量不足时运行多变量测试。 这是最常见的错误。流量被摊得太薄,组合永远达不到显著性,结果要么不明确,要么具有误导性。
一次测试太多变量。 复杂度会叠加。先从最可能带来显著差异的变量开始,而不是测试所有能测的元素。
在问题是单因素时使用多变量测试。 如果你想知道标题 A 还是标题 B 转化更好,那就是 A/B 测试。多变量测试只会增加开销,却不会增加相关洞察。
没有假设就上线测试。 没有假设的测试只是观察练习。上线前先明确你预期会发生什么,以及为什么会发生,这样结果才能验证或挑战某个具体想法。
跨渠道混用指标。 如果“转化”的定义在不同测试组或不同渠道之间不一致,结果就无法解读。上线前先锁定指标定义。
过早停止测试。 早期结果噪音很大。在某个版本刚刚领先、却还没达到统计显著性时就停止测试,是得出错误结论的最可靠方式之一。
如何选择正确的方法
按以下问题顺序思考:
你要改动多少东西? 如果只有一个,用 A/B 测试。如果有多个,可以考虑多变量测试,但前提是流量支撑得住。
你的流量够吗? 如果你无法在合理时间内为每个组合提供足够样本,那就改为顺序 A/B 测试。
你在寻找交互效应吗? 如果元素 A 是否有效取决于元素 B,那你需要多变量测试;如果不是,就不需要。
你需要多快得到答案? A/B 测试更快达到显著性。如果活动窗口很短,A/B 几乎总是更好的选择。
你真正问的问题是什么? 要具体。模糊的问题会产生无法提供有用答案的实验,不管你用哪种方法都一样。
创意产能在这里扮演什么角色
关于广告创意中的 A/B 测试和多变量测试,讨论常常卡在方法论层面。但更大的现实约束通常是制作能力:如果你只能产出 2 个创意版本,就不可能测试 10 个。
对于投放付费社媒的电商和 DTC 品牌来说,创意测试在结构上几乎总是 A/B 形式(一个切入点对另一个、一个视觉风格对另一个),但产能很重要。你能轮换的创意版本越多,你就越快学到什么有效,也越能抵御创意疲劳带来的下滑。Creatify 的 URL 转视频 和 素材生成器 工具正是为此而存在:生成足够多的创意版本,让你真正运行一套测试系统,而不是只投一两个广告就称之为测试。
LAIFE 使用 Creatify 后,每周测试的视频数量从 10 个提升到 50 个,而创意输入量的提升,直接支撑了那套测试系统,最终将他们在 TikTok 上的每单成本降到了 3.89 美元。
方法很重要,拥有足够多的创意来使用它,同样重要。
常见问题
A/B 测试和多变量测试有什么区别?
A/B 测试比较单个元素的两个版本,以确定哪个表现更好,每次只改变一个变量。多变量测试同时评估多个变量,找出哪种组合表现最佳,以及各元素之间是否存在交互。A/B 测试更简单、更快;多变量测试能提供更深入的洞察,但需要显著更多的流量。
我应该什么时候使用 A/B 测试,什么时候使用多变量测试?
当你的问题只涉及一个变量、流量有限,或者你需要快速得到结果时,用 A/B 测试。当多个元素可能相互作用、你拥有高流量,并且你需要理解是什么变量组合驱动了表现,而不只是哪个单一元素胜出时,用多变量测试。
什么是多变量定向?
多变量定向是指在不同受众细分中测试不同的创意、文案、优惠或版式组合,以识别哪种组合对每个群体表现最好。它在受众规模和活动流量足够大、能够支撑每个测试组合的有效样本量时最有效。
多变量测试需要多少流量?
没有统一阈值,但原则是每种组合都需要足够流量来达到统计显著性。变量越多,组合越多;组合越多,所需流量就越大。如果流量有限,顺序 A/B 测试通常比摊得太薄的多变量测试更可靠。
什么是多变量测试(multivariable test)?
Multivariable test 是一个非正式术语,有时与 multivariate test 互换使用。在正式统计和实验设计中,更被接受的术语是 multivariate testing,指同时评估多个变量的实验,包括它们的主效应和交互效应。这个非正式用法因行业和工具而异。
最好的多变量测试工具有哪些?
优秀的实验平台应同时支持 A/B 和多变量工作流,能够在各组合之间清晰分配流量,并提供能呈现交互效应而不仅仅是总体赢家的报告。合适的工具取决于你要测试什么:网站页面、邮件活动和广告创意各自有不同的平台要求。优先选择支持实验治理和清晰报告的工具,而不是只会替换创意版本的工具。
什么是多渠道营销中的 A/B 测试?
多渠道营销中的 A/B 测试,是指在多个渠道中同时或顺序运行受控实验,并在每个渠道使用相同的成功指标。你可以同时测试 Meta 上的广告创意、邮件主题行,以及付费搜索中的落地页版本。关键在于一致性:所有渠道使用相同的转化定义,这样结果才可比较、可解读。
我可以同时运行 A/B 测试和多变量测试吗?
可以,只要它们测试的是不同元素,或者针对不同受众细分且没有重叠。把重叠实验同时投放给同一受众,会引入混杂效应,使两个测试的结果都不可靠。













