


Tim Creatify
BAGIKAN



DALAM ARTIKEL INI
Sebagian besar pembuat video AI memberikan Anda uncanny valley - mulut yang bergerak, mata yang tidak, tubuh yang tetap beku seperti potongan karton. Aurora dibangun untuk memperbaiki itu.

Aurora adalah model diffusion transformer (DiT) milik Creatify untuk sintesis avatar berbasis audio. Beri satu foto dan klip audio, dan ia menghasilkan video berkualitas studio dari orang tersebut berbicara, menyajikan, atau bernyanyi - dengan ekspresi wajah yang disinkronkan, gerakan mata alami, pernapasan, dan gerakan tubuh bagian atas sepenuhnya. Ini bukan hanya sinkronisasi bibir. Ini adalah pertunjukan penuh.
Model tersebut telah diintegrasikan ke dalam ElevenLabs, Runware dan fal.ai sebagai salah satu model generasi video pertama - sinyal kemana arah generasi video AI menuju.
Panduan ini membahas cara mendapatkan hasil terbaik darinya.
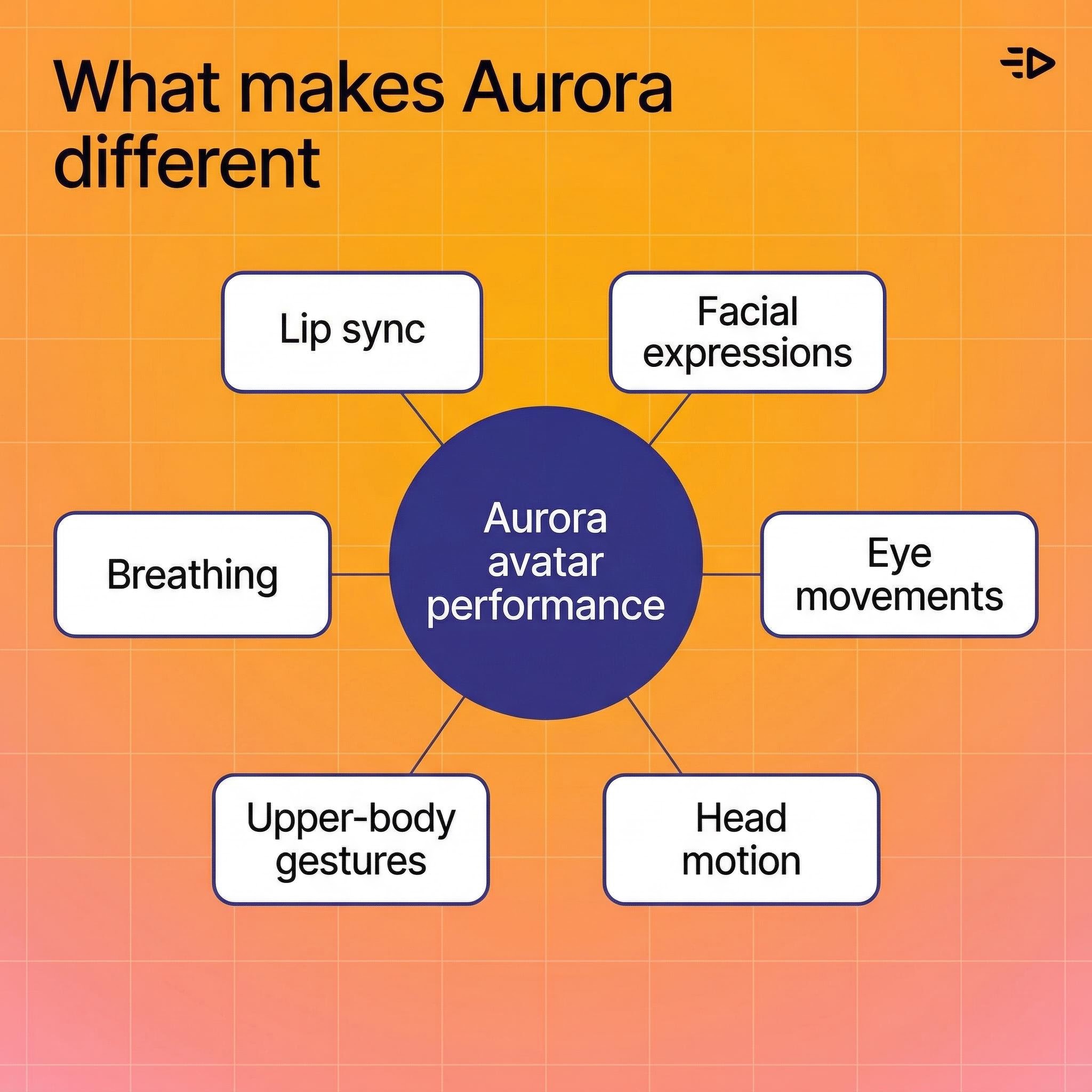
Apa yang membuat Aurora berbeda
Sebagian besar alat berbicara-turis menggerakkan mulut dan menyelesaikannya. Aurora menganggap avatar sebagai orang utuh, menetapkan standar baru untuk generasi video AI yang realistis.
Inilah yang sebenarnya dihasilkan oleh model:
Sinkronisasi bibir yang melacak audio secara akurat, termasuk bentuk mulut halus untuk fonem yang berbeda
Ekspresi wajah yang sesuai dengan nada vokal dan penyampaian emosional
Gerakan mata - berkedip, pergeseran pandangan, fokus alami
Gerakan kepala - anggukan, kemiringan, perubahan posisi halus
Gerakan tubuh bagian atas - gerakan tangan, pergeseran bahu, jenis gerakan alami yang membuat kepala berbicara terasa nyata daripada robotik
Pernapasan - gerakan dada antara kalimat
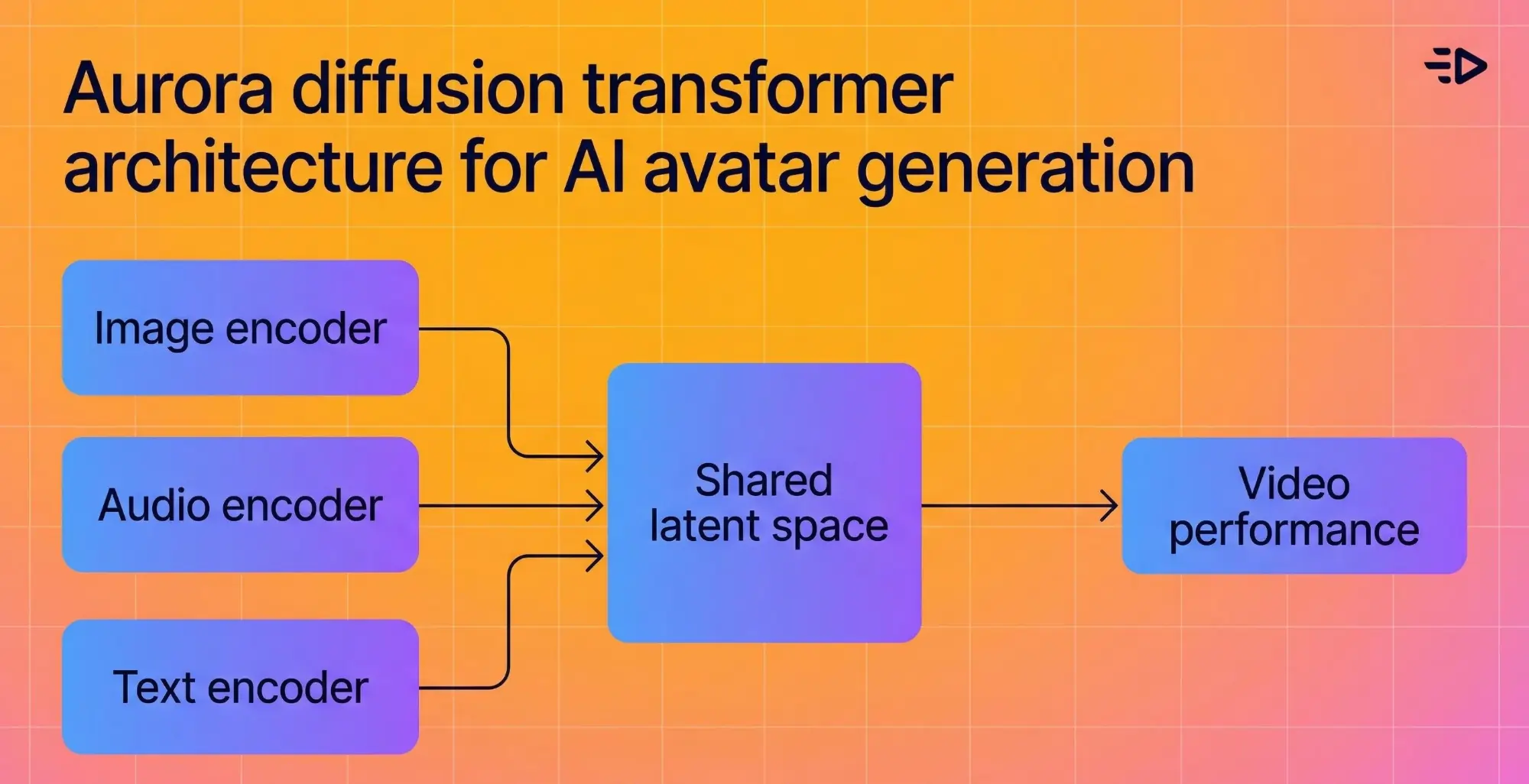
Arsitektur dasar menggabungkan encoder gambar, encoder teks, dan encoder audio ke dalam ruang laten bersama, sehingga model memahami konteks emosional dari apa yang dikatakan dan mencerminkannya secara visual. Jika audio terdengar antusias, avatar terlihat antusias.
Apa yang dapat Anda bangun dengannya

Aurora mendukung sejumlah besar jenis konten di luar kepala berbicara sederhana, menjadikannya alat yang kuat untuk alur kerja generasi video ai:
Demo produk - Menampilkan seseorang memegang produk, menunjuk padanya, dan menjelaskan keuntungannya. Berfungsi untuk produk perawatan kulit, teknologi, barang konsumsi, apa saja.
Iklan gaya UGC - Format selfie, sedikit goyang kamera genggam, penyampaian santai. Sulit dibedakan dari konten kreator asli.
Klip podcast - Wajah avatar sedikit menghadap ke samping seakan berbicara kepada co-host, dengan ekspresi aktif dan percakapan.
Konten multibahasa - Menghasilkan video yang sama dalam bahasa apa pun tanpa harus merekam ulang. Aurora menjaga gerakan bibir avatar tetap sinkron dengan audio baru.
Avatar bernyanyi - Berikan grafis album dan lagu, dan avatar akan membawakannya. Berguna untuk pemasaran musik atau konten hiburan.
Karakter animasi - Bekerja dengan karakter bergambar dan seni bergaya, bukan hanya foto realistis.
Mendapatkan hasil terbaik dengan generasi video AI
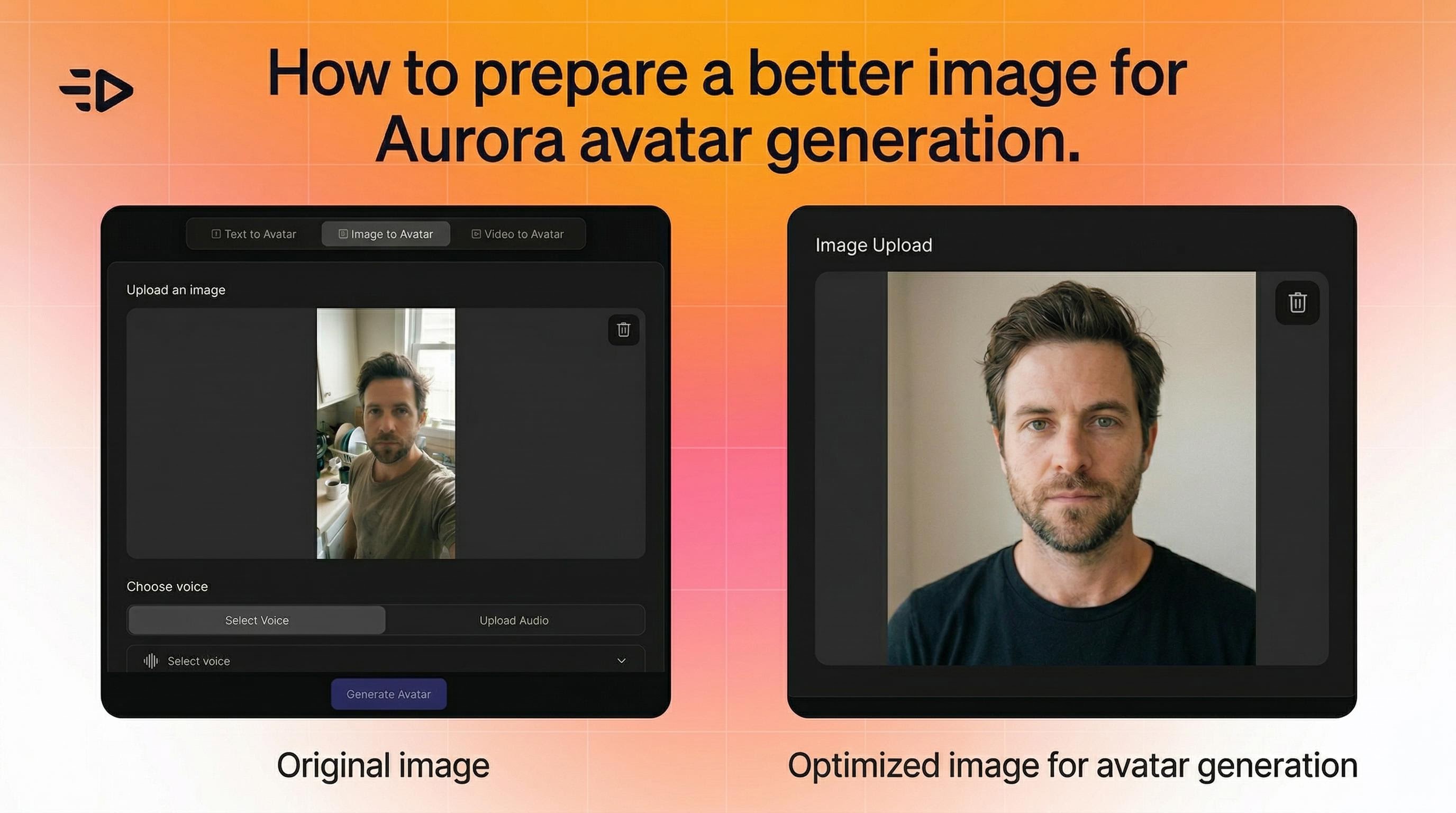
1. Mulai dengan gambar yang tepat
Aurora fleksibel - ia bekerja dengan foto, render, dan seni karakter. Tetapi beberapa hal membantu:
Subyek harus terlihat jelas dan dapat dikenali dalam bingkai
Untuk video multi-adegan yang konsisten, pertahankan pemotretan yang serupa di semua gambar (misalnya, semua potret)
Jika gerakan terlihat tidak alami, cobalah gambar dengan pose yang lebih bersih dan netral
Tidak ada batasan ketat pada sudut, pencahayaan, atau komposisi. Aurora menyesuaikan secara dinamis.
2. Gunakan Model Suara V3
Ini tidak bisa ditawar untuk hasil berkualitas. Model Suara V3 memberikan sinkronisasi bibir yang paling akurat dan jangkauan ekspresif terluas. Model suara yang lebih lama menghasilkan output yang terlihat lebih buruk.
Jaga kecepatan bicara moderat dan jelas. Jika sinkronisasi terasa sedikit tidak cocok, memperlambat suara sedikit biasanya memperbaikinya. Tambahkan jeda alami antara kalimat - ini memberi avatar ruang untuk bernapas dan membuat penampilan terasa lebih manusiawi.
3. Kuasai prompt Anda
Di sinilah kebanyakan orang meninggalkan hasil di meja. Prompt memberi tahu Aurora bagaimana avatar harus berperilaku - bukan hanya seperti apa bentuknya, tetapi bagaimana ia bergerak, emosi apa yang disampaikan, dan bagaimana ia berinteraksi dengan adegan.
Gunakan ini sebagai prompt dasar Anda untuk video kepala berbicara standar:
Wawancara studio 4K, close-up sedang (crop hingga bahu). Latar belakang abu-abu terang yang mulus, pencahayaan kunci lembut seragam - tidak ada perubahan pencahayaan. Penyaji menghadap kamera, kontak mata tetap. Tangan tetap di bawah bingkai, tubuh benar-benar diam. Sangat tajam.
Dari sana, lapis dengan petunjuk perilaku yang spesifik untuk kasus penggunaan Anda.
Contoh Prompt berdasarkan format:
Kasus Penggunaan | Prompt Perilaku yang Ditambahkan |
|---|---|
Demo produk | Orang yang memegang produk menunjukkan label menghadap kamera sambil menjelaskan, menunjuk padanya dari waktu ke waktu. |
Kepala berbicara yang alami | Orang tersebut berbicara dan menghadap kamera secara langsung dan alami dengan gerakan dada yang bernapas. Isyarat penjelasan yang alami dan gerakan mata. |
Podcast | Orang tersebut melihat dan menghadap ke samping seolah-olah berbicara dengan seseorang di arah itu, dengan ekspresi menarik yang menunjukkan minat pada topik tersebut. |
Selfie UGC | Orang tersebut berbicara di depan kamera dengan satu tangan tidak terlihat. Kamera sedikit bergoyang seolah dipegang dengan tangan. |
Ulasan produk yang antusias | Tangan orang tersebut bergerak dengan antusias mencoba menjelaskan manfaat produk. |
Semakin spesifik Anda dengan nada emosional dan perilaku fisik, semakin baik outputnya. Prompter samar menghasilkan hasil generik.
Tip Pro: Gunakan GPT untuk menggabungkan pengaturan sinematik dasar Anda dengan kasus penggunaan spesifik Anda. Promot: "Buat prompt Aurora yang dioptimalkan untuk demo produk [X]" dan itu akan menggabungkan pembingkaian teknis dengan petunjuk perilaku yang tepat secara otomatis.
4. Sesuaikan arah_prompt
Aurora memiliki parameter prompt_guidance yang berkisar dari 0 hingga 4. Ini mengontrol seberapa ketat model mengikuti prompt Anda dibandingkan dengan memungkinkan variasi alami.
Mulai pada 1 untuk sebagian besar adegan. Ini memberi model ruang untuk tampil alami sambil tetap mengikuti arahan.
Naikkan jika avatar melenceng dari prompt atau tidak mengikuti petunjuk perilaku yang Anda tetapkan.
Turunkan jika performanya terasa kaku atau mekanis.
5. Sesuaikan audio, gambar, dan prompt secara emosional
Kesalahan paling umum: menggunakan trek audio yang energetik dan ceria dengan gambar berprestasi netral dan prompt perilaku yang tenang. Model menggabungkan semua tiga input. Jika mereka menarik ke arah yang berbeda, hasilnya terasa tidak konsisten.
Jika audio Anda antusias, prompt Anda harus memanggil perilaku yang energetik dan ekspresif. Jika tenang dan informatif, prompt Anda harus mencerminkan itu. Semakin selaras ketiga input ini, semakin meyakinkan hasilnya.
Pemecahan masalah cepat
Masalah | Perbaikan |
|---|---|
Sinkronisasi bibir terasa tidak cocok | Perlambat sedikit kecepatan suara |
Gerakan terlihat tidak alami | Coba gambar lain dengan pose yang lebih bersih |
Avatar melenceng dari prompt | Tingkatkan prompt_guidance |
Performanya terasa terlalu robotik | Kurangi prompt_guidance; tambahkan petunjuk perilaku yang lebih lembut |
Ketidakonsistenan di seluruh adegan | Gunakan gambar dengan pembingkaian dan gaya yang serupa |

Gambaran yang lebih besar
Aurora mewakili langkah maju yang berarti dalam generasi video AI — bukan karena itu adalah hal baru, tetapi karena memecahkan masalah produksi yang nyata. Membuat video avatar berkualitas tinggi dulu membutuhkan kamera, studio, performer, dan alur kerja pasca-produksi. Sekarang dibutuhkan sebuah foto dan skrip.
Bagi pemasar kinerja yang menjalankan kampanye berbayar, itu mengubah perhitungan pada pengujian kreatif. Bagi agensi yang mengelola banyak klien, itu mengubah ekonomi produksi video. Bagi siapa pun yang pernah melewatkan iklan video karena biaya atau kompleksitas, itu menghilangkan hambatannya sepenuhnya.
Model ini aktif di Creatify, dan integrasi dengan ElevenLabs, Runware, dan fal.ai berarti semakin mudah diakses sebagai kemampuan mandiri bagi pengembang dan pencipta yang membangun di atas infrastruktur AI.
Satu foto. Satu klip audio. Sebuah video yang terlihat seperti Anda merekamnya di studio.
Sebagian besar pembuat video AI memberikan Anda uncanny valley - mulut yang bergerak, mata yang tidak, tubuh yang tetap beku seperti potongan karton. Aurora dibangun untuk memperbaiki itu.
Aurora adalah model diffusion transformer (DiT) milik Creatify untuk sintesis avatar berbasis audio. Beri satu foto dan klip audio, dan ia menghasilkan video berkualitas studio dari orang tersebut berbicara, menyajikan, atau bernyanyi - dengan ekspresi wajah yang disinkronkan, gerakan mata alami, pernapasan, dan gerakan tubuh bagian atas sepenuhnya. Ini bukan hanya sinkronisasi bibir. Ini adalah pertunjukan penuh.
Model tersebut telah diintegrasikan ke dalam ElevenLabs, Runware dan fal.ai sebagai salah satu model generasi video pertama - sinyal kemana arah generasi video AI menuju.
Panduan ini membahas cara mendapatkan hasil terbaik darinya.
Apa yang membuat Aurora berbeda
Sebagian besar alat berbicara-turis menggerakkan mulut dan menyelesaikannya. Aurora menganggap avatar sebagai orang utuh, menetapkan standar baru untuk generasi video AI yang realistis.
Inilah yang sebenarnya dihasilkan oleh model:
Sinkronisasi bibir yang melacak audio secara akurat, termasuk bentuk mulut halus untuk fonem yang berbeda
Ekspresi wajah yang sesuai dengan nada vokal dan penyampaian emosional
Gerakan mata - berkedip, pergeseran pandangan, fokus alami
Gerakan kepala - anggukan, kemiringan, perubahan posisi halus
Gerakan tubuh bagian atas - gerakan tangan, pergeseran bahu, jenis gerakan alami yang membuat kepala berbicara terasa nyata daripada robotik
Pernapasan - gerakan dada antara kalimat
Arsitektur dasar menggabungkan encoder gambar, encoder teks, dan encoder audio ke dalam ruang laten bersama, sehingga model memahami konteks emosional dari apa yang dikatakan dan mencerminkannya secara visual. Jika audio terdengar antusias, avatar terlihat antusias.
Apa yang dapat Anda bangun dengannya
Aurora mendukung sejumlah besar jenis konten di luar kepala berbicara sederhana, menjadikannya alat yang kuat untuk alur kerja generasi video ai:
Demo produk - Menampilkan seseorang memegang produk, menunjuk padanya, dan menjelaskan keuntungannya. Berfungsi untuk produk perawatan kulit, teknologi, barang konsumsi, apa saja.
Iklan gaya UGC - Format selfie, sedikit goyang kamera genggam, penyampaian santai. Sulit dibedakan dari konten kreator asli.
Klip podcast - Wajah avatar sedikit menghadap ke samping seakan berbicara kepada co-host, dengan ekspresi aktif dan percakapan.
Konten multibahasa - Menghasilkan video yang sama dalam bahasa apa pun tanpa harus merekam ulang. Aurora menjaga gerakan bibir avatar tetap sinkron dengan audio baru.
Avatar bernyanyi - Berikan grafis album dan lagu, dan avatar akan membawakannya. Berguna untuk pemasaran musik atau konten hiburan.
Karakter animasi - Bekerja dengan karakter bergambar dan seni bergaya, bukan hanya foto realistis.
Mendapatkan hasil terbaik dengan generasi video AI
1. Mulai dengan gambar yang tepat
Aurora fleksibel - ia bekerja dengan foto, render, dan seni karakter. Tetapi beberapa hal membantu:
Subyek harus terlihat jelas dan dapat dikenali dalam bingkai
Untuk video multi-adegan yang konsisten, pertahankan pemotretan yang serupa di semua gambar (misalnya, semua potret)
Jika gerakan terlihat tidak alami, cobalah gambar dengan pose yang lebih bersih dan netral
Tidak ada batasan ketat pada sudut, pencahayaan, atau komposisi. Aurora menyesuaikan secara dinamis.
2. Gunakan Model Suara V3
Ini tidak bisa ditawar untuk hasil berkualitas. Model Suara V3 memberikan sinkronisasi bibir yang paling akurat dan jangkauan ekspresif terluas. Model suara yang lebih lama menghasilkan output yang terlihat lebih buruk.
Jaga kecepatan bicara moderat dan jelas. Jika sinkronisasi terasa sedikit tidak cocok, memperlambat suara sedikit biasanya memperbaikinya. Tambahkan jeda alami antara kalimat - ini memberi avatar ruang untuk bernapas dan membuat penampilan terasa lebih manusiawi.
3. Kuasai prompt Anda
Di sinilah kebanyakan orang meninggalkan hasil di meja. Prompt memberi tahu Aurora bagaimana avatar harus berperilaku - bukan hanya seperti apa bentuknya, tetapi bagaimana ia bergerak, emosi apa yang disampaikan, dan bagaimana ia berinteraksi dengan adegan.
Gunakan ini sebagai prompt dasar Anda untuk video kepala berbicara standar:
Wawancara studio 4K, close-up sedang (crop hingga bahu). Latar belakang abu-abu terang yang mulus, pencahayaan kunci lembut seragam - tidak ada perubahan pencahayaan. Penyaji menghadap kamera, kontak mata tetap. Tangan tetap di bawah bingkai, tubuh benar-benar diam. Sangat tajam.
Dari sana, lapis dengan petunjuk perilaku yang spesifik untuk kasus penggunaan Anda.
Contoh Prompt berdasarkan format:
Kasus Penggunaan | Prompt Perilaku yang Ditambahkan |
|---|---|
Demo produk | Orang yang memegang produk menunjukkan label menghadap kamera sambil menjelaskan, menunjuk padanya dari waktu ke waktu. |
Kepala berbicara yang alami | Orang tersebut berbicara dan menghadap kamera secara langsung dan alami dengan gerakan dada yang bernapas. Isyarat penjelasan yang alami dan gerakan mata. |
Podcast | Orang tersebut melihat dan menghadap ke samping seolah-olah berbicara dengan seseorang di arah itu, dengan ekspresi menarik yang menunjukkan minat pada topik tersebut. |
Selfie UGC | Orang tersebut berbicara di depan kamera dengan satu tangan tidak terlihat. Kamera sedikit bergoyang seolah dipegang dengan tangan. |
Ulasan produk yang antusias | Tangan orang tersebut bergerak dengan antusias mencoba menjelaskan manfaat produk. |
Semakin spesifik Anda dengan nada emosional dan perilaku fisik, semakin baik outputnya. Prompter samar menghasilkan hasil generik.
Tip Pro: Gunakan GPT untuk menggabungkan pengaturan sinematik dasar Anda dengan kasus penggunaan spesifik Anda. Promot: "Buat prompt Aurora yang dioptimalkan untuk demo produk [X]" dan itu akan menggabungkan pembingkaian teknis dengan petunjuk perilaku yang tepat secara otomatis.
4. Sesuaikan arah_prompt
Aurora memiliki parameter prompt_guidance yang berkisar dari 0 hingga 4. Ini mengontrol seberapa ketat model mengikuti prompt Anda dibandingkan dengan memungkinkan variasi alami.
Mulai pada 1 untuk sebagian besar adegan. Ini memberi model ruang untuk tampil alami sambil tetap mengikuti arahan.
Naikkan jika avatar melenceng dari prompt atau tidak mengikuti petunjuk perilaku yang Anda tetapkan.
Turunkan jika performanya terasa kaku atau mekanis.
5. Sesuaikan audio, gambar, dan prompt secara emosional
Kesalahan paling umum: menggunakan trek audio yang energetik dan ceria dengan gambar berprestasi netral dan prompt perilaku yang tenang. Model menggabungkan semua tiga input. Jika mereka menarik ke arah yang berbeda, hasilnya terasa tidak konsisten.
Jika audio Anda antusias, prompt Anda harus memanggil perilaku yang energetik dan ekspresif. Jika tenang dan informatif, prompt Anda harus mencerminkan itu. Semakin selaras ketiga input ini, semakin meyakinkan hasilnya.
Pemecahan masalah cepat
Masalah | Perbaikan |
|---|---|
Sinkronisasi bibir terasa tidak cocok | Perlambat sedikit kecepatan suara |
Gerakan terlihat tidak alami | Coba gambar lain dengan pose yang lebih bersih |
Avatar melenceng dari prompt | Tingkatkan prompt_guidance |
Performanya terasa terlalu robotik | Kurangi prompt_guidance; tambahkan petunjuk perilaku yang lebih lembut |
Ketidakonsistenan di seluruh adegan | Gunakan gambar dengan pembingkaian dan gaya yang serupa |
Gambaran yang lebih besar
Aurora mewakili langkah maju yang berarti dalam generasi video AI — bukan karena itu adalah hal baru, tetapi karena memecahkan masalah produksi yang nyata. Membuat video avatar berkualitas tinggi dulu membutuhkan kamera, studio, performer, dan alur kerja pasca-produksi. Sekarang dibutuhkan sebuah foto dan skrip.
Bagi pemasar kinerja yang menjalankan kampanye berbayar, itu mengubah perhitungan pada pengujian kreatif. Bagi agensi yang mengelola banyak klien, itu mengubah ekonomi produksi video. Bagi siapa pun yang pernah melewatkan iklan video karena biaya atau kompleksitas, itu menghilangkan hambatannya sepenuhnya.
Model ini aktif di Creatify, dan integrasi dengan ElevenLabs, Runware, dan fal.ai berarti semakin mudah diakses sebagai kemampuan mandiri bagi pengembang dan pencipta yang membangun di atas infrastruktur AI.
Satu foto. Satu klip audio. Sebuah video yang terlihat seperti Anda merekamnya di studio.












